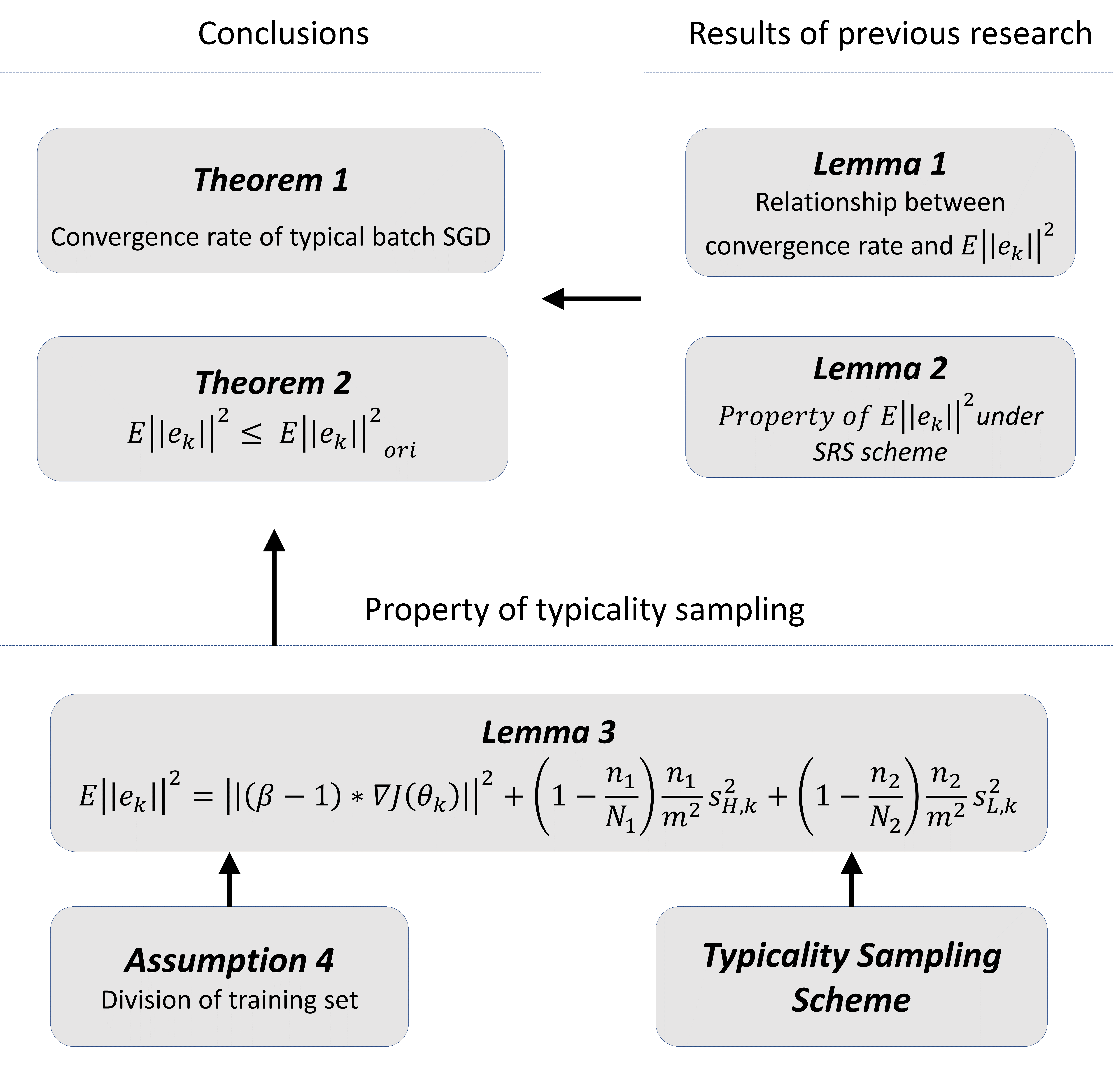
Machine learning, especially deep neural networks, has been rapidly developed in fields including computer vision, speech recognition and reinforcement learning. Although Mini-batch SGD is one of the most popular stochastic optimization methods in training deep networks, it shows a slow convergence rate due to the large noise in gradient approximation. In this paper, we attempt to remedy this problem by building more efficient batch selection method based on typicality sampling, which reduces the error of gradient estimation in conventional Minibatch SGD. We analyze the convergence rate of the resulting typical batch SGD algorithm and compare convergence properties between Minibatch SGD and the algorithm. Experimental results demonstrate that our batch selection scheme works well and more complex Minibatch SGD variants can benefit from the proposed batch selection strategy.
翻译:机械学习,特别是深神经网络,已在计算机视觉、语音识别和强化学习等领域迅速发展,尽管微型批量SGD是培训深网络最受欢迎的随机优化方法之一,但由于梯度近似中的噪音很大,它显示出缓慢的趋同率。在本文中,我们试图通过建立基于典型抽样的更高效的批量选择方法来解决这个问题,这种方法可以减少传统小型批量SGD中梯度估计的误差。我们分析了由此产生的典型批次SGD算法的趋同率,并比较了Minibatch SGD与算法之间的趋同性。实验结果表明,我们的批次选择计划运作良好,而更复杂的小型批次 SGD变体可以受益于拟议的批次选择战略。