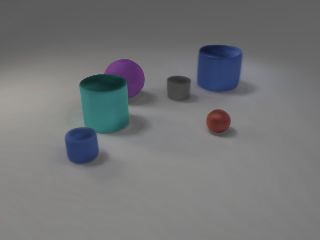We present ObSuRF, a method which turns a single image of a scene into a 3D model represented as a set of Neural Radiance Fields (NeRFs), with each NeRF corresponding to a different object. A single forward pass of an encoder network outputs a set of latent vectors describing the objects in the scene. These vectors are used independently to condition a NeRF decoder, defining the geometry and appearance of each object. We make learning more computationally efficient by deriving a novel loss, which allows training NeRFs on RGB-D inputs without explicit ray marching. After confirming that the model performs equal or better than state of the art on three 2D image segmentation benchmarks, we apply it to two multi-object 3D datasets: A multiview version of CLEVR, and a novel dataset in which scenes are populated by ShapeNet models. We find that after training ObSuRF on RGB-D views of training scenes, it is capable of not only recovering the 3D geometry of a scene depicted in a single input image, but also to segment it into objects, despite receiving no supervision in that regard.
翻译:我们展示了ObSuRF, 这种方法将场景的单一图像转换成3D模型, 代表了一组神经辐射场( NeRFs), 每个 NeRF 对应不同的对象。 编码器网络的单个前端输出了一系列描述场景中对象的潜向矢量。 这些矢量被独立用于设置一个 NeRF 解码器, 定义每个对象的几何和外观。 我们通过得出新的损失来提高学习的计算效率, 从而可以对 RGB- D 输入的 NERF 进行没有明确的射线行进式的培训。 在确认该模型在三个 2D 图像分割基准上的表现等于或优于艺术状态之后, 我们将其应用到两个多点 3D 数据集: CLEVR 的多视图版本, 以及一个由 ShapeNet 模型所覆盖的场景的新型数据集。 我们发现, 在对 ObSuRF 进行关于 RGB- D 培训场景的训练后, 它不仅能够恢复在单个输入图像中描述的场景的 3D 几何, 但也 。