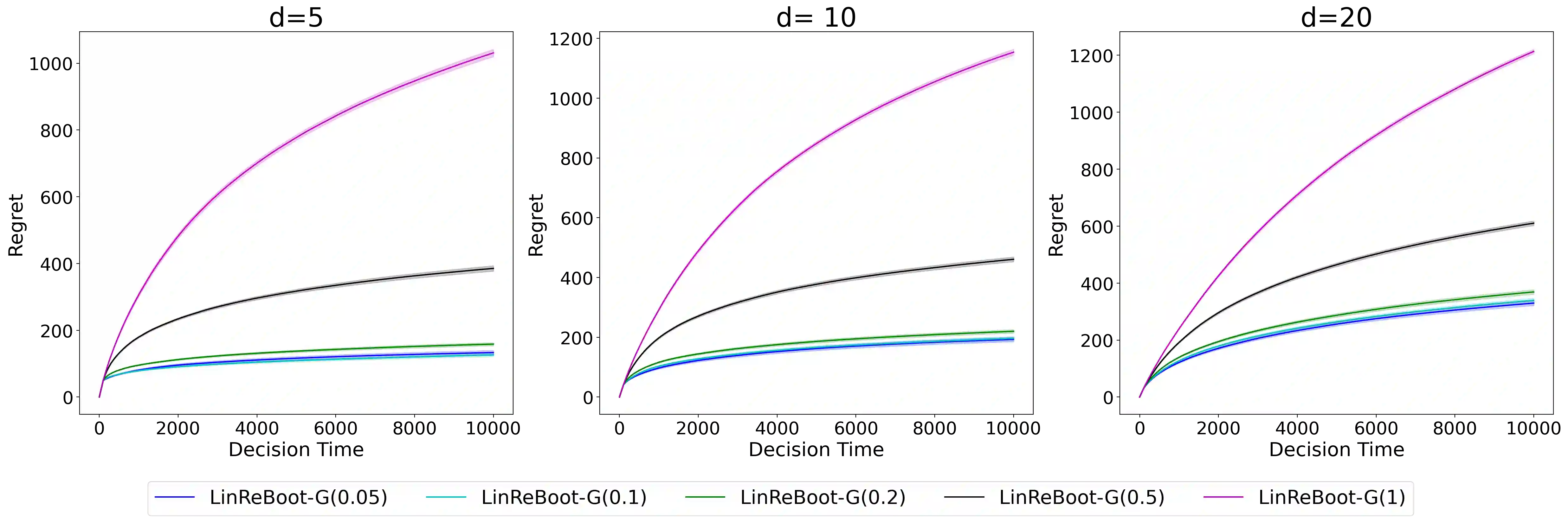
We propose a new bootstrap-based online algorithm for stochastic linear bandit problems. The key idea is to adopt residual bootstrap exploration, in which the agent estimates the next step reward by re-sampling the residuals of mean reward estimate. Our algorithm, residual bootstrap exploration for stochastic linear bandit (\texttt{LinReBoot}), estimates the linear reward from its re-sampling distribution and pulls the arm with the highest reward estimate. In particular, we contribute a theoretical framework to demystify residual bootstrap-based exploration mechanisms in stochastic linear bandit problems. The key insight is that the strength of bootstrap exploration is based on collaborated optimism between the online-learned model and the re-sampling distribution of residuals. Such observation enables us to show that the proposed \texttt{LinReBoot} secure a high-probability $\tilde{O}(d \sqrt{n})$ sub-linear regret under mild conditions. Our experiments support the easy generalizability of the \texttt{ReBoot} principle in the various formulations of linear bandit problems and show the significant computational efficiency of \texttt{LinReBoot}.
翻译:我们提出一个新的基于靴子陷阱的在线算法,用于处理沙发线性土匪问题。 关键的想法是采用残余靴子陷阱勘探法, 使代理人通过重新取样平均报酬估计的剩余值来估计下一步的奖励。 我们的算法, 残余靴子陷阱探索法, 用于随机线性线性土匪(\ titt{ LinReBooot}), 估计其再抽样分布的线性奖励, 并用最高的报酬估计来拉动手臂。 特别是, 我们贡献了一个理论框架, 在沙发线性土匪问题中解开残余靴子陷阱调查机制的神秘化。 关键的认识是, 靴子探索的力度是基于在线学习模型和重新取样剩余值分布的合作乐观。 这样的观察让我们能够显示, 拟议的 拖子{ LinBooot} 保证高概率 $\ tite{ O} (d\ qrt{n} $ 子线性脊髓。 我们的实验支持了在轻度条件下,\ texttrodual developtions produtions rodution roductions rotibal roduction room roomd.