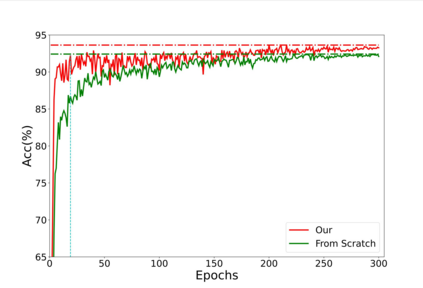
Masked language modeling (MLM) has become one of the most successful self-supervised pre-training task. Inspired by its success, Point-BERT, as a pioneer work in point cloud, proposed masked point modeling (MPM) to pre-train point transformer on large scale unanotated dataset. Despite its great performance, we find the inherent difference between language and point cloud tends to cause ambiguous tokenization for point cloud. For point cloud, there doesn't exist a gold standard for point cloud tokenization. Point-BERT use a discrete Variational AutoEncoder (dVAE) as tokenizer, but it might generate different token ids for semantically-similar patches and generate the same token ids for semantically-dissimilar patches. To tackle above problem, we propose our McP-BERT, a pre-training framework with multi-choice tokens. Specifically, we ease the previous single-choice constraint on patch token ids in Point-BERT, and provide multi-choice token ids for each patch as supervision. Moreover, we utilitze the high-level semantics learned by transformer to further refine our supervision signals. Extensive experiments on point cloud classification, few-shot classification and part segmentation tasks demonstrate the superiority of our method, e.g., the pre-trained transformer achieves 94.1% accuracy on ModelNet40, 84.28% accuracy on the hardest setting of ScanObjectNN and new state-of-the-art performance on few-shot learning. We also demonstrate that our method not only improves the performance of Point-BERT on all downstream tasks, but also incurs almost no extra computational overhead. The code will be released in https://github.com/fukexue/McP-BERT.
翻译:蒙面语言建模( MLM) 已经成为最成功的自我监督的训练前自我监督任务之一。 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点- 点