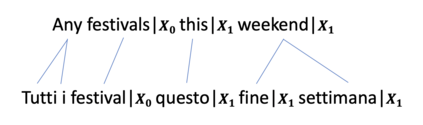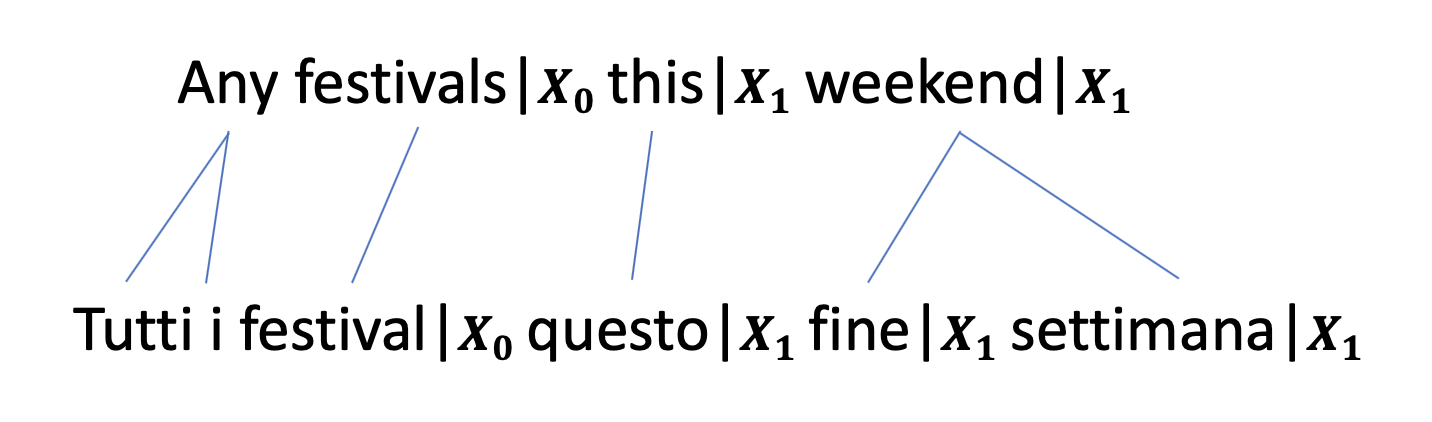Multilingual semantic parsing is a cost-effective method that allows a single model to understand different languages. However, researchers face a great imbalance of availability of training data, with English being resource rich, and other languages having much less data. To tackle the data limitation problem, we propose using machine translation to bootstrap multilingual training data from the more abundant English data. To compensate for the data quality of machine translated training data, we utilize transfer learning from pretrained multilingual encoders to further improve the model. To evaluate our multilingual models on human-written sentences as opposed to machine translated ones, we introduce a new multilingual semantic parsing dataset in English, Italian and Japanese based on the Facebook Task Oriented Parsing (TOP) dataset. We show that joint multilingual training with pretrained encoders substantially outperforms our baselines on the TOP dataset and outperforms the state-of-the-art model on the public NLMaps dataset. We also establish a new baseline for zero-shot learning on the TOP dataset. We find that a semantic parser trained only on English data achieves a zero-shot performance of 44.9% exact-match accuracy on Italian sentences.
翻译:多语言语义解析是一种具有成本效益的方法,它使单一模型能够理解不同的语言。然而,研究人员面临着培训数据可用性的巨大不平衡,因为英语资源丰富,而其他语言的数据则少得多。为了解决数据限制问题,我们建议使用机器翻译,从更丰富的英语数据中引出多语种培训数据。为了补偿机器翻译培训数据的数据质量,我们利用预先培训的多语种解析器的学习来进一步改进模型。为了评估我们关于人写句而非机器翻译的多语言模型,我们根据Facebook任务定位解析数据集,采用了一个新的英语、意大利语和日语多语言解析数据集。我们发现,与预先培训的编码编码器联合进行的多语种培训大大超出了我们在TOP数据集上的基线,也超过了公共的NLMaps数据集上最先进的模型。我们还为在TOP数据集上零点解析学习新基线。我们发现,只有经过英语数据精确度培训的语义分析器才能达到44的准确度。