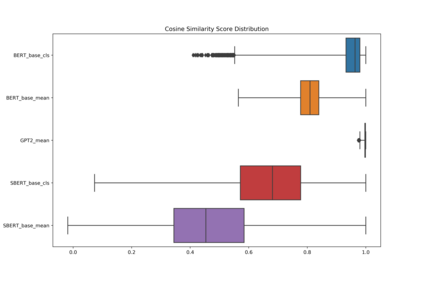
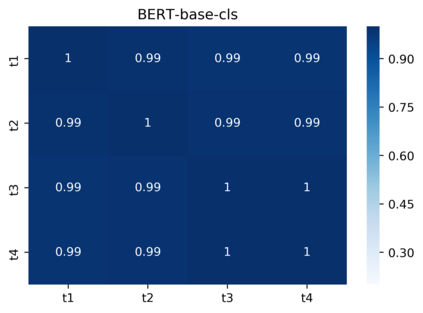
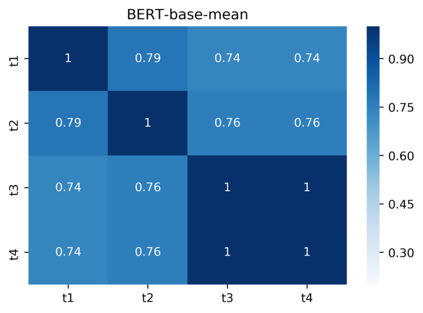
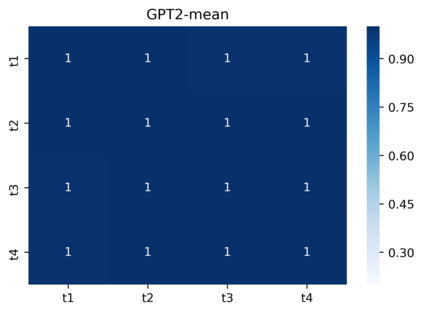
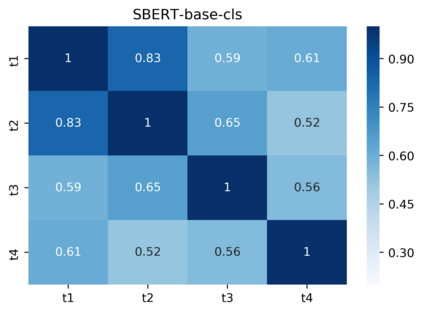
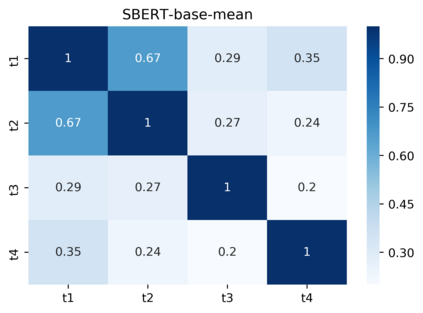
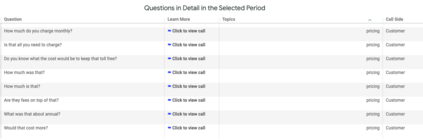
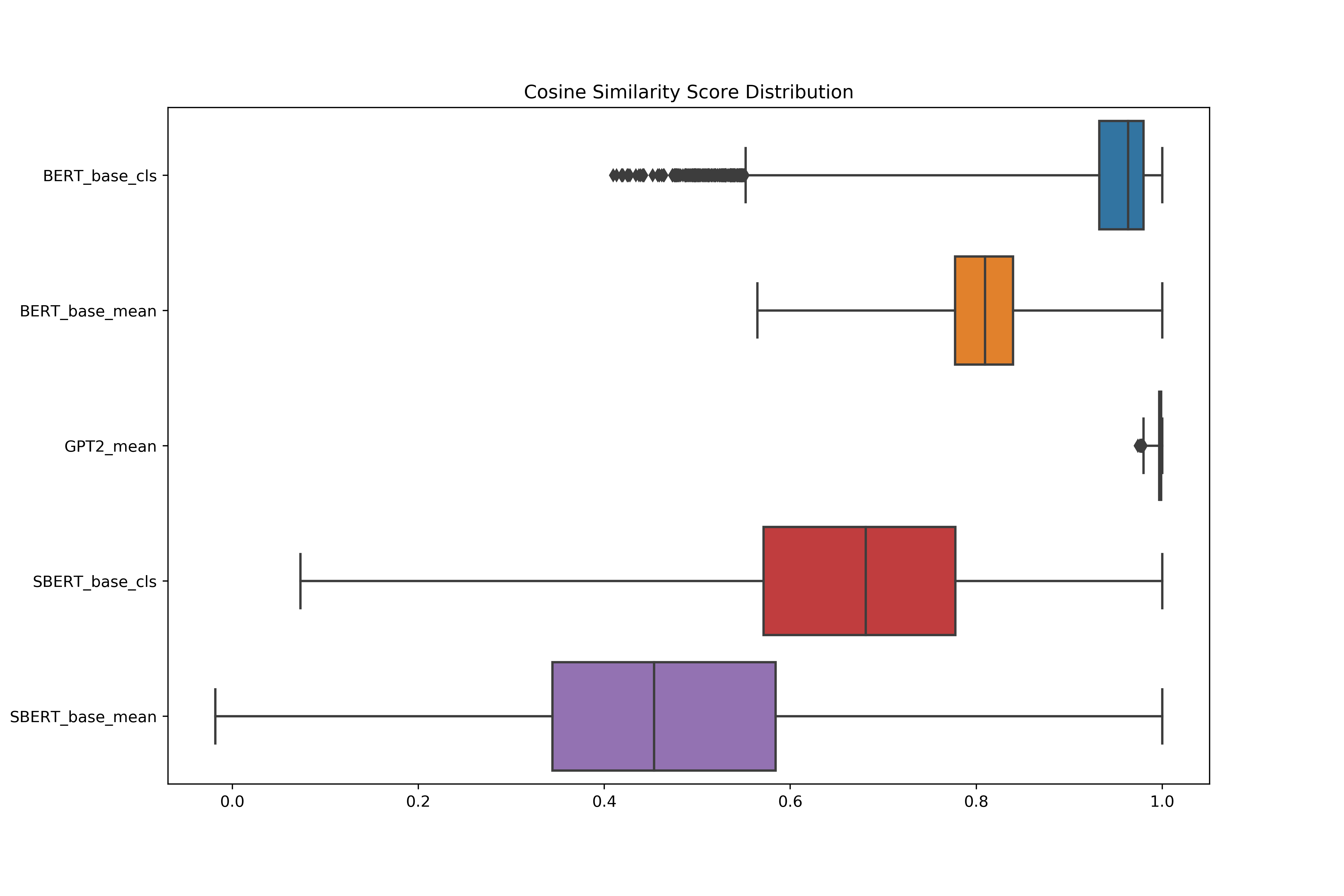
Pre-trained contextualized embedding models such as BERT are a standard building block in many natural language processing systems. We demonstrate that the sentence-level representations produced by some off-the-shelf contextualized embedding models have a narrow distribution in the embedding space, and thus perform poorly for the task of identifying semantically similar questions in real-world English business conversations. We describe a method that uses appropriately tuned representations and a small set of exemplars to group questions of interest to business users in a visualization that can be used for data exploration or employee coaching.
翻译:培训前背景化嵌入模型(如BERT)是许多自然语言处理系统的一个标准基石。我们证明,一些现成背景化嵌入模型生成的句级表述在嵌入空间的分布很窄,因此在确定真实世界英语商业对话中的语义相似问题的任务方面表现不佳。我们描述了一种方法,即使用适当调整的表述和一套小型示范,将商业用户感兴趣的问题归为可视化,可用于数据探索或员工辅导。