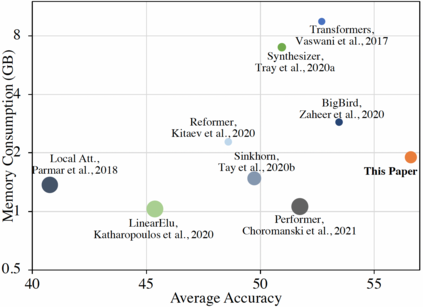
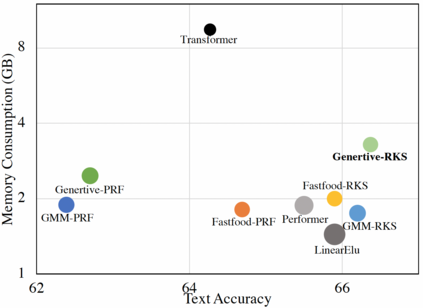
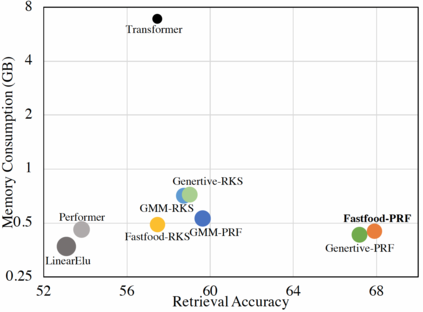
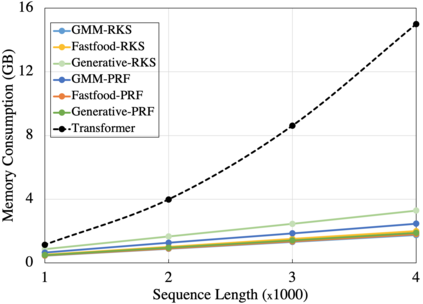
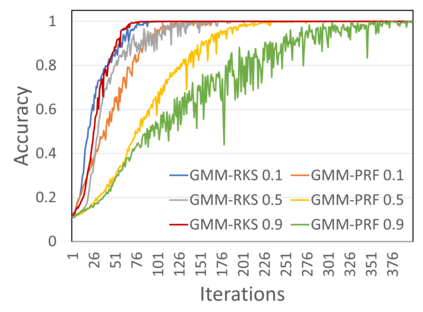
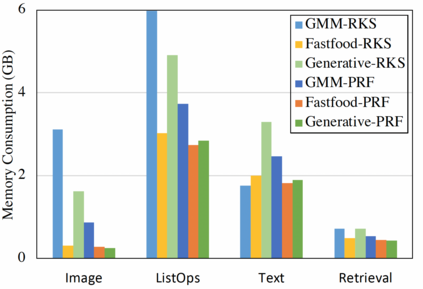
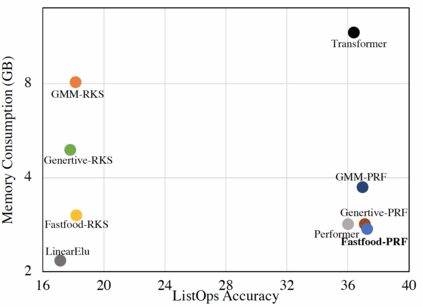
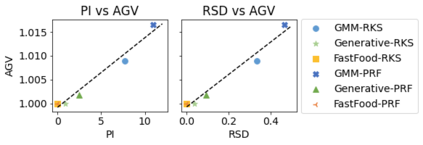
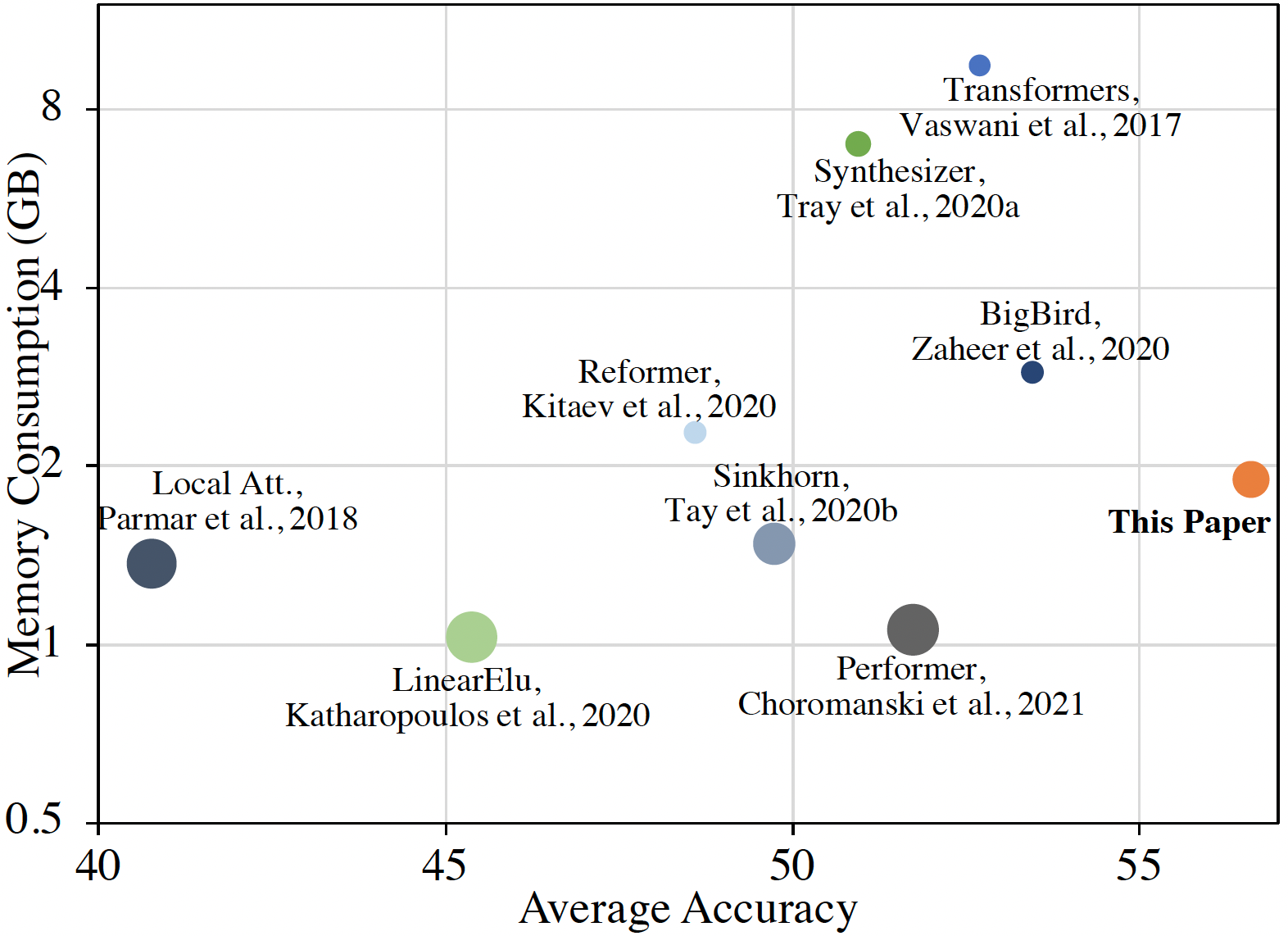
In this work we introduce KERNELIZED TRANSFORMER, a generic, scalable, data driven framework for learning the kernel function in Transformers. Our framework approximates the Transformer kernel as a dot product between spectral feature maps and learns the kernel by learning the spectral distribution. This not only helps in learning a generic kernel end-to-end, but also reduces the time and space complexity of Transformers from quadratic to linear. We show that KERNELIZED TRANSFORMERS achieve performance comparable to existing efficient Transformer architectures, both in terms of accuracy as well as computational efficiency. Our study also demonstrates that the choice of the kernel has a substantial impact on performance, and kernel learning variants are competitive alternatives to fixed kernel Transformers, both in long as well as short sequence tasks.
翻译:在这项工作中,我们引入了KERNELIZED Transformerc,这是一个用于在变换器中学习内核函数的通用、可扩展的数据驱动框架。我们的框架将变换器内核作为光谱地貌图之间的圆点产品,并通过学习光谱分布来学习内核。这不仅有助于学习通用内核端到端,而且会减少变换器从二次变换到线性的时间和空间复杂性。我们显示,KERNELIZED TransformercS在准确性和计算效率两方面都取得了与现有高效变换器结构相类似的性能。我们的研究还表明,内核的选择对性能有重大影响,而内核学习变异体是固定内核变体的竞争性替代物,既可以长也可以短顺序任务。