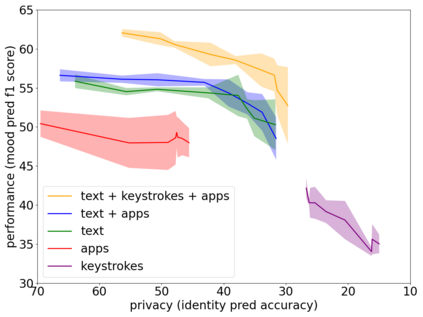
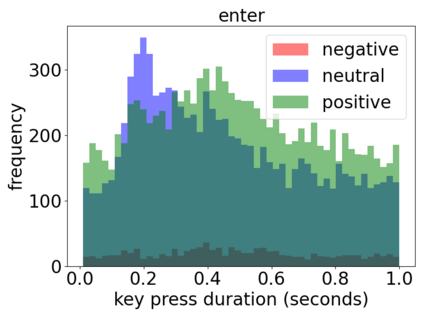
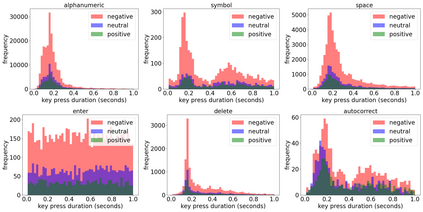
Mental health conditions remain underdiagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications for the early detection, intervention, and treatment of mental health disorders. One promising data source to help monitor human behavior is daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected (e.g., race, gender) attributes. In this paper, we study behavioral markers of daily mood using a recent dataset of mobile behaviors from adolescent populations at high risk of suicidal behaviors. Using computational models, we find that language and multimodal representations of mobile typed text (spanning typed characters, words, keystroke timings, and app usage) are predictive of daily mood. However, we find that models trained to predict mood often also capture private user identities in their intermediate representations. To tackle this problem, we evaluate approaches that obfuscate user identity while remaining predictive. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier.
翻译:即使在有共同获得先进医疗护理机会的国家,心理健康状况仍然未得到充分诊断; 能够准确和有效地预测容易收集的数据对早期发现、干预和治疗心理健康疾病具有一些重要影响。 有助于监测人类行为的有希望的数据来源之一是日常智能手机的使用。然而,必须注意总结行为,而不通过个人(如个人可识别的信息)或受保护(如种族、性别)属性来识别用户。本文利用来自高危自杀行为青少年的移动行为的最新数据集,我们研究日常生活中的行为标志。我们使用计算模型发现,移动类型文字的语言和多模式(包括打字字符、字、键盘时间和应用程序使用)是预测日常情绪的。然而,我们发现,为预测情绪而培训的模式往往也在其中间表达中捕捉私人用户身份。为了解决这一问题,我们评估了在继续预测的同时模糊用户身份的方法。通过将多式表达与隐私保留学习相结合,我们能够推进性能偏差前沿。