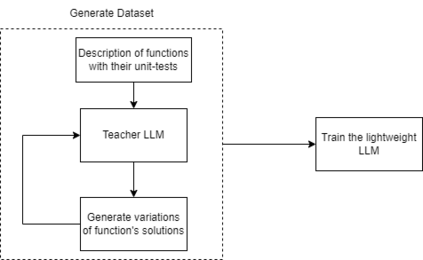
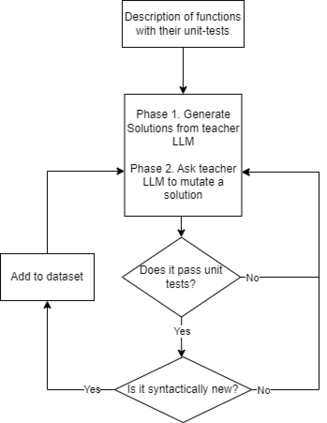
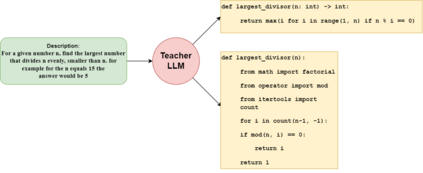
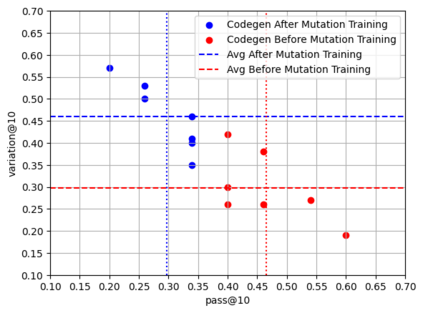
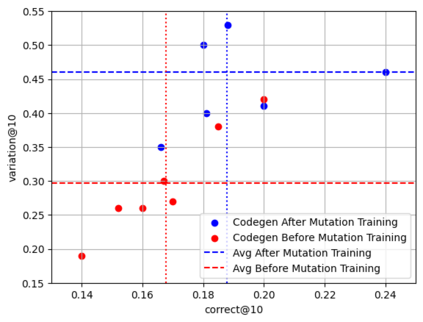
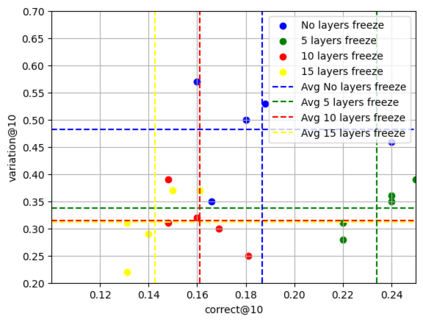
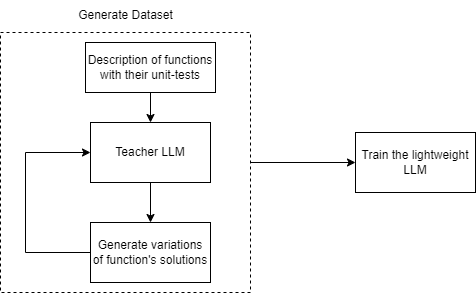
Recent advancements in Large Language Models (LLMs) have significantly improved their capabilities in natural language processing and code synthesis, enabling more complex applications across different fields. This paper explores the application of LLMs in the context of code mutation, a process where the structure of program code is altered without changing its functionality. Traditionally, code mutation has been employed to increase software robustness in mission-critical applications. Additionally, mutation engines have been exploited by malware developers to evade the signature-based detection methods employed by malware detection systems. Existing code mutation engines, often used by such threat actors, typically result in only limited variations in the malware, which can still be identified through static code analysis. However, the agility demonstrated by an LLM-based code synthesizer could significantly change this threat landscape by allowing for more complex code mutations that are not easily detected using static analysis. One can increase variations of codes synthesized by a pre-trained LLM through fine-tuning and retraining. This process is what we refer to as code mutation training. In this paper, we propose a novel definition of code mutation training tailored for pre-trained LLM-based code synthesizers and demonstrate this training on a lightweight pre-trained model. Our approach involves restructuring (i.e., mutating) code at the subroutine level, which allows for more manageable mutations while maintaining the semantic integrity verified through unit testing. Our experimental results illustrate the effectiveness of our approach in improving code mutation capabilities of LLM-based program synthesizers in producing varied and functionally correct code solutions, showcasing their potential to transform the landscape of code mutation and the threats associated with it.
翻译:暂无翻译