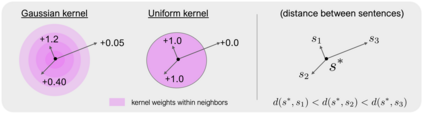
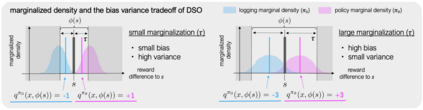
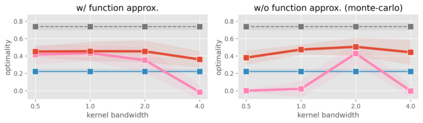
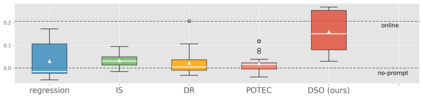
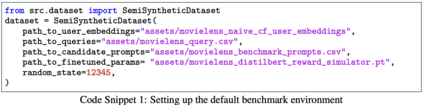
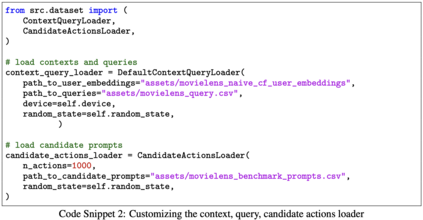
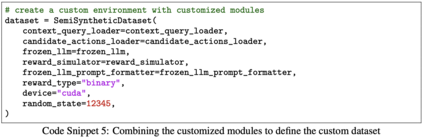
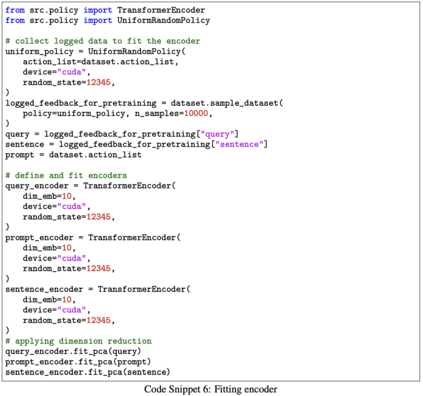
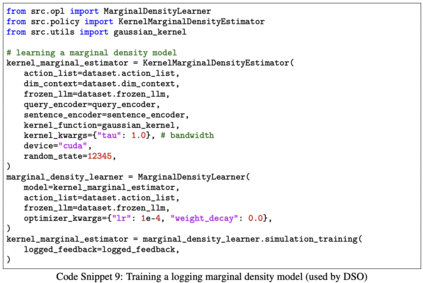
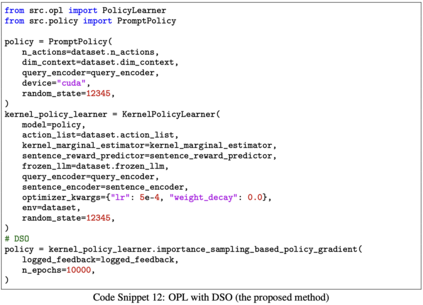
We study how to use naturally available user feedback, such as clicks, to optimize large language model (LLM) pipelines for generating personalized sentences using prompts. Naive approaches, which estimate the policy gradient in the prompt space, suffer either from variance caused by the large action space of prompts or bias caused by inaccurate reward predictions. To circumvent these challenges, we propose a novel kernel-based off-policy gradient method, which estimates the policy gradient by leveraging similarity among generated sentences, substantially reducing variance while suppressing the bias. Empirical results on our newly established suite of benchmarks demonstrate the effectiveness of the proposed approach in generating personalized descriptions for movie recommendations, particularly when the number of candidate prompts is large.
翻译:暂无翻译