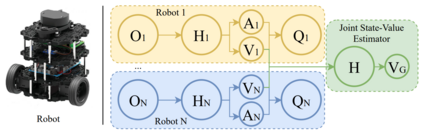
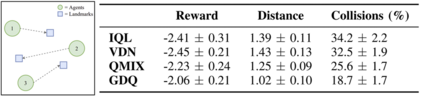
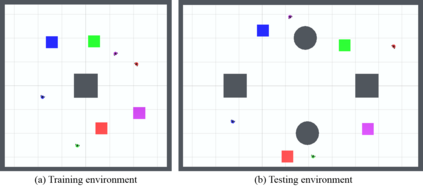
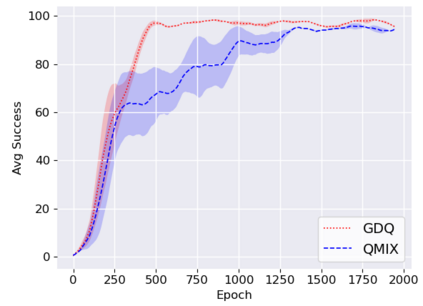
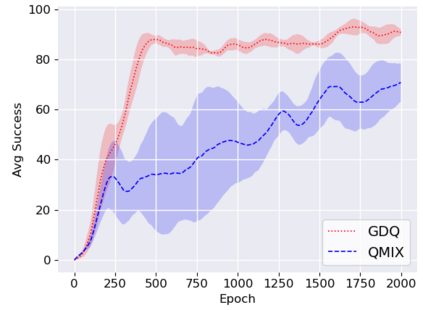
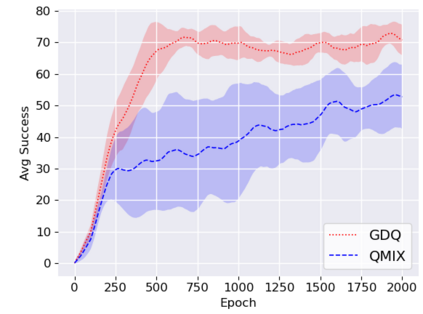
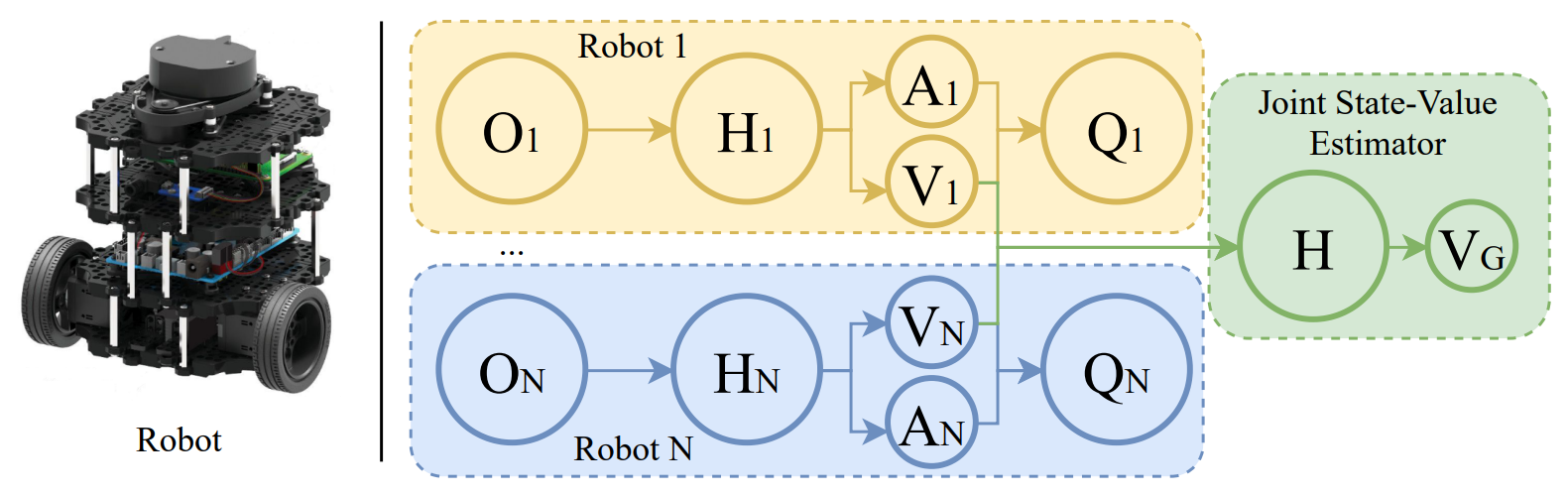
We study the problem of multi-robot mapless navigation in the popular Centralized Training and Decentralized Execution (CTDE) paradigm. This problem is challenging when each robot considers its path without explicitly sharing observations with other robots and can lead to non-stationary issues in Deep Reinforcement Learning (DRL). The typical CTDE algorithm factorizes the joint action-value function into individual ones, to favor cooperation and achieve decentralized execution. Such factorization involves constraints (e.g., monotonicity) that limit the emergence of novel behaviors in an individual as each agent is trained starting from a joint action-value. In contrast, we propose a novel architecture for CTDE that uses a centralized state-value network to compute a joint state-value, which is used to inject global state information in the value-based updates of the agents. Consequently, each model computes its gradient update for the weights, considering the overall state of the environment. Our idea follows the insights of Dueling Networks as a separate estimation of the joint state-value has both the advantage of improving sample efficiency, while providing each robot information whether the global state is (or is not) valuable. Experiments in a robotic navigation task with 2 4, and 8 robots, confirm the superior performance of our approach over prior CTDE methods (e.g., VDN, QMIX).
翻译:我们在流行的中央化培训和分散执行(CTDE)范式中研究多机器人无地图导航问题。当每个机器人考虑其路径时,不与其他机器人明确分享观测结果,并可能导致深强化学习(DRL)中的非静止问题时,这一问题具有挑战性。典型的CTDE算法因素将联合行动-价值功能转化为单个功能,有利于合作,实现分散执行。这种因素化涉及限制个人新行为的出现(例如单调性),因为每个代理人都从联合行动-价值开始接受培训。相反,我们建议为CTDE建立一个新的结构,利用中央化的国家-价值网络来计算共同的国家-价值,用于在基于价值的代理人更新中输入全球国家信息。因此,每个模型都计算其权重值的梯度更新,同时考虑到环境的总体状况。我们的想法是将裁断N网络作为对联合国家价值的单独估计,其优点是提高样品效率,同时提供每个机器人的样本效率,同时提供中央化的状态-价值网络来计算一个共同的国家-价值网络,用来在基于价值的更新过程中输入全球机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人-机器人