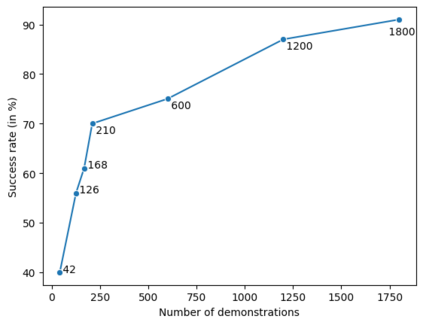
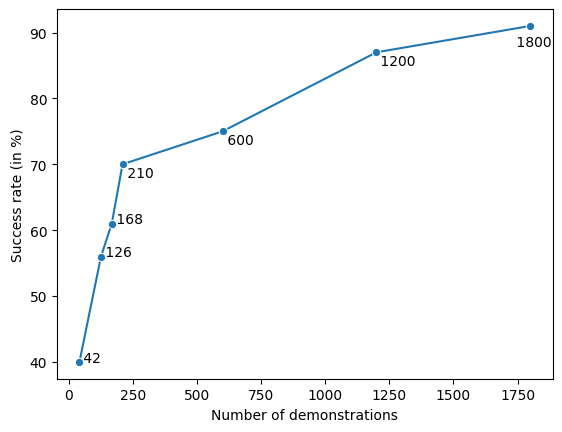
Pretrained language models demonstrate strong performance in most NLP tasks when fine-tuned on small task-specific datasets. Hence, these autoregressive models constitute ideal agents to operate in text-based environments where language understanding and generative capabilities are essential. Nonetheless, collecting expert demonstrations in such environments is a time-consuming endeavour. We introduce a two-stage procedure to learn from a small set of demonstrations and further improve by interacting with an environment. We show that language models fine-tuned with only 1.2% of the expert demonstrations and a simple reinforcement learning algorithm achieve a 51% absolute improvement in success rate over existing methods in the ALFWorld environment.
翻译:在微调小型任务数据集时,预先培训的语言模式在大多数国家劳工政策任务中表现良好。因此,这些自动递减模式是理想的推动者,可以在基于文本的环境下运作,因为语言理解和感化能力至关重要。然而,在这种环境中收集专家演示是一个耗时的工作。我们引入了两阶段程序,从少量示范中学习,并通过与环境互动进一步改进。我们显示,语言模式经过微调,只对1.2%的专家演示和简单的强化学习算法进行了微调,在ALFWorld环境中,相对于现有方法的成功率实现了51%的绝对提高。