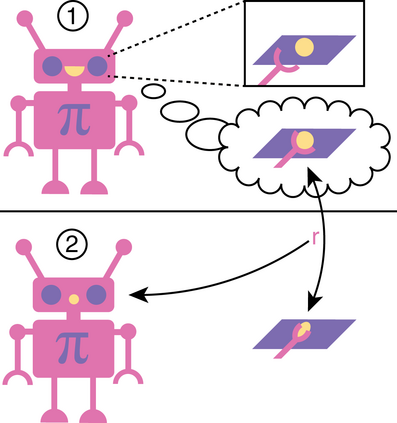
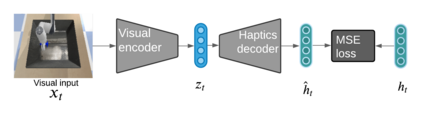
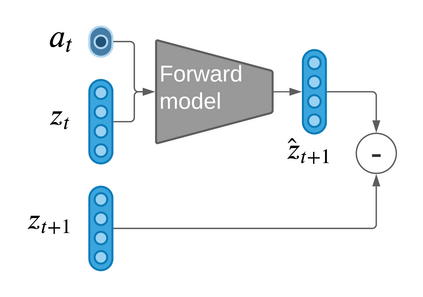
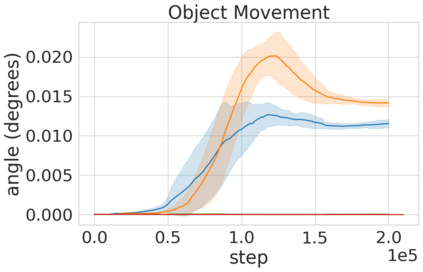
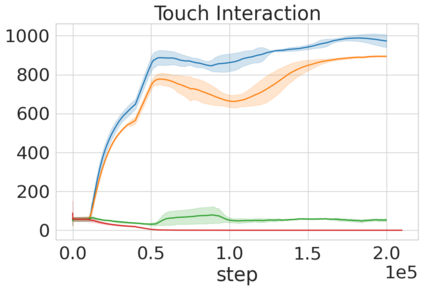
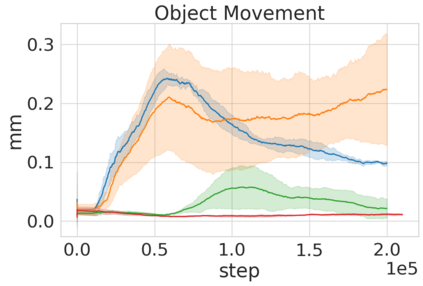
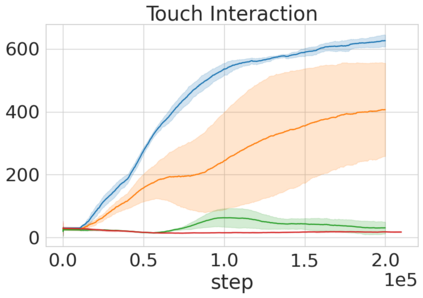
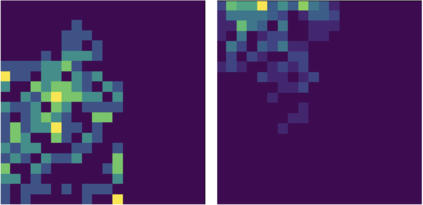
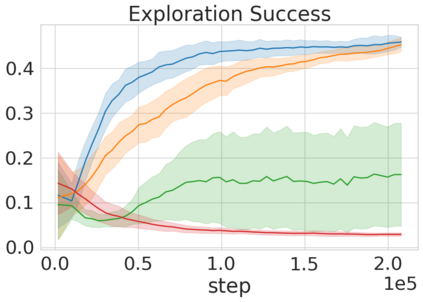
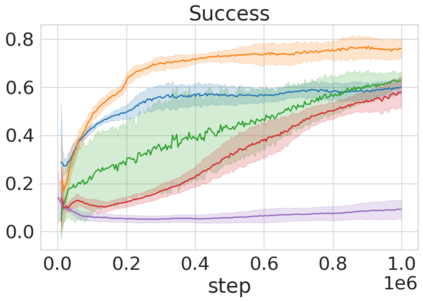
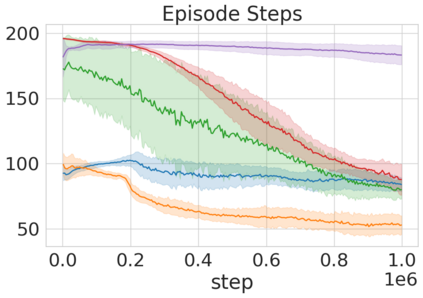
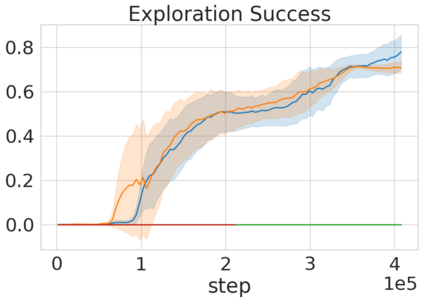
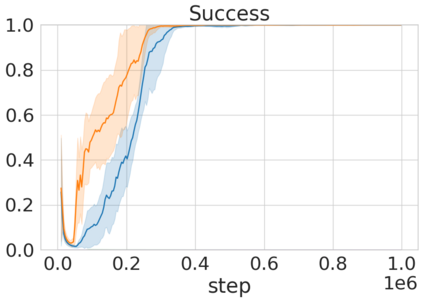
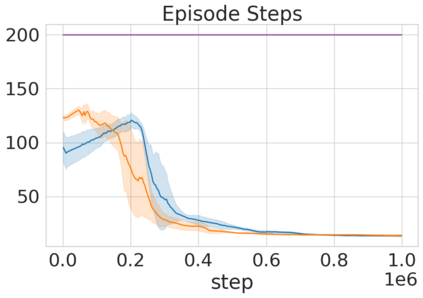
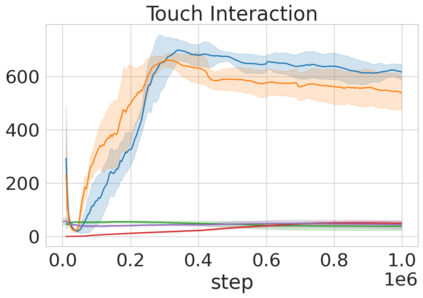
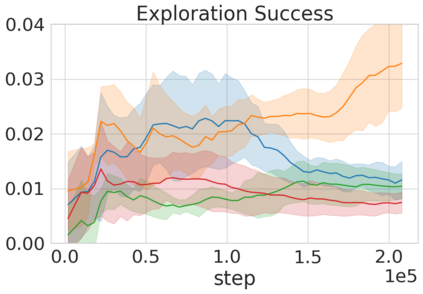
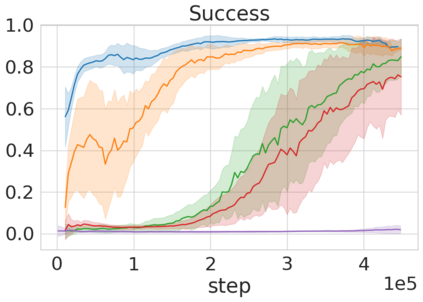
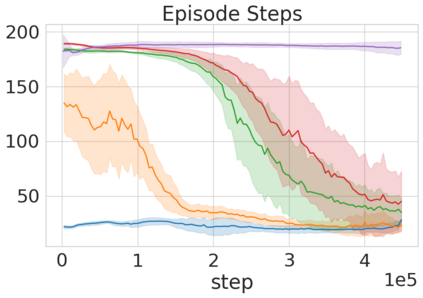
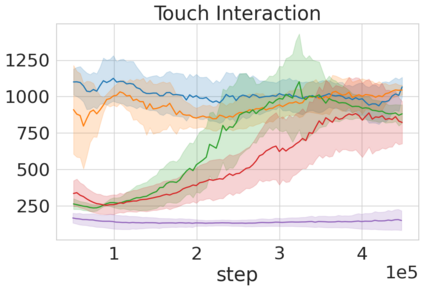
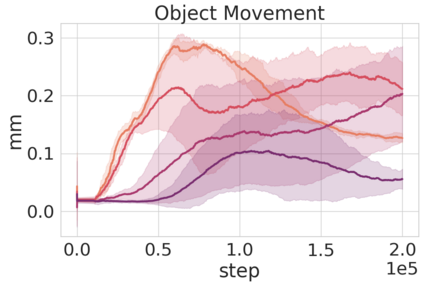
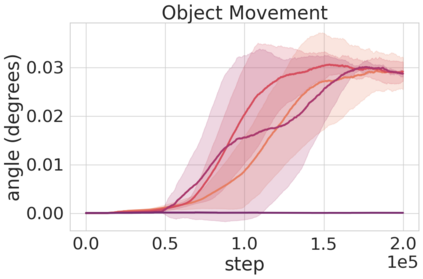
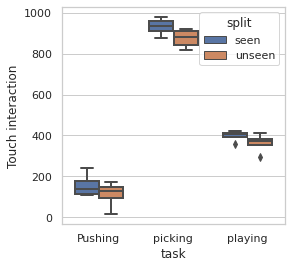
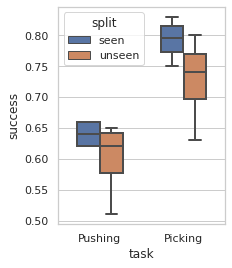
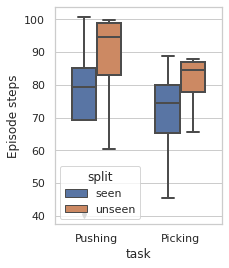
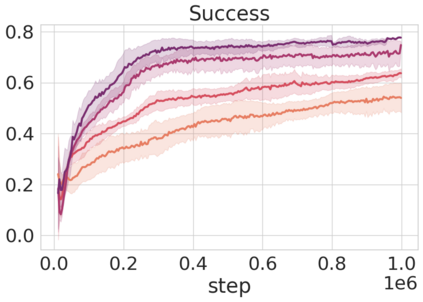
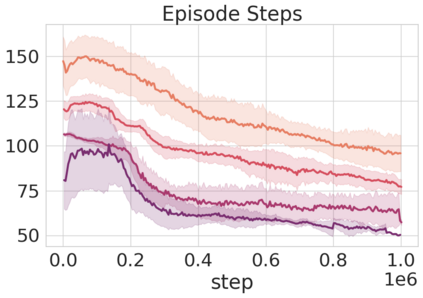
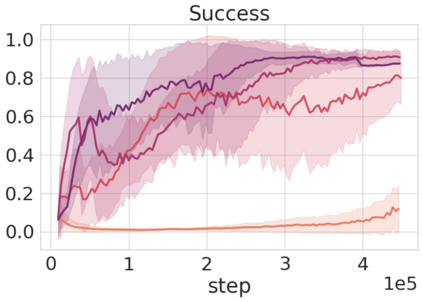
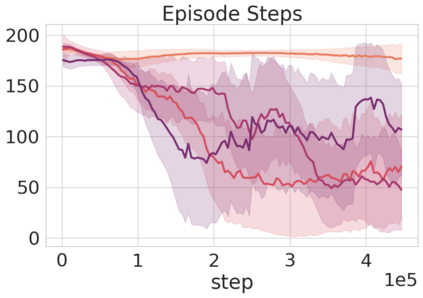
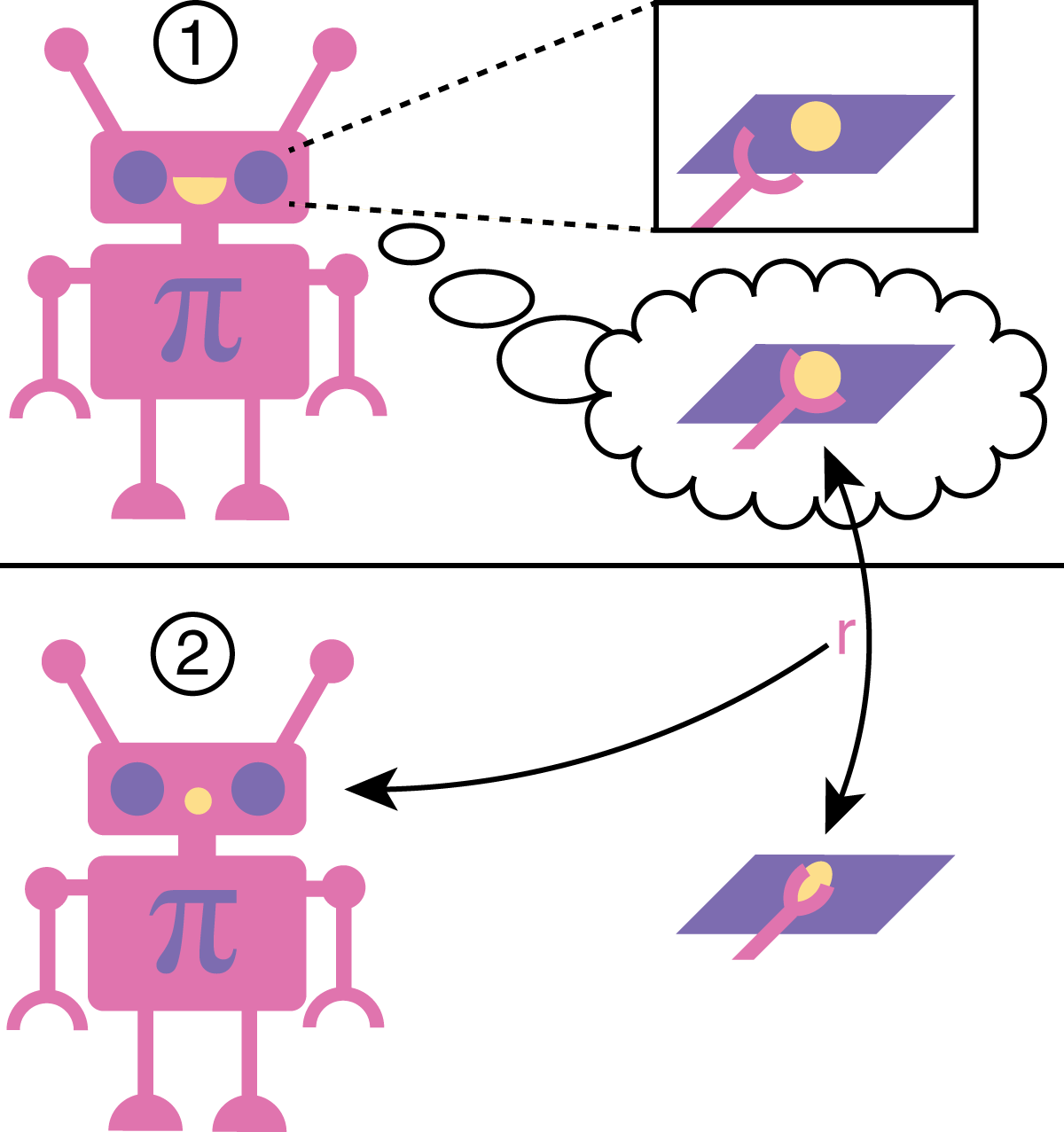
Robots in many real-world settings have access to force/torque sensors in their gripper and tactile sensing is often necessary in tasks that involve contact-rich motion. In this work, we leverage surprise from mismatches in touch feedback to guide exploration in hard sparse-reward reinforcement learning tasks. Our approach, Touch-based Curiosity (ToC), learns what visible objects interactions are supposed to "feel" like. We encourage exploration by rewarding interactions where the expectation and the experience don't match. In our proposed method, an initial task-independent exploration phase is followed by an on-task learning phase, in which the original interactions are relabeled with on-task rewards. We test our approach on a range of touch-intensive robot arm tasks (e.g. pushing objects, opening doors), which we also release as part of this work. Across multiple experiments in a simulated setting, we demonstrate that our method is able to learn these difficult tasks through sparse reward and curiosity alone. We compare our cross-modal approach to single-modality (touch- or vision-only) approaches as well as other curiosity-based methods and find that our method performs better and is more sample-efficient.
翻译:在许多现实世界环境中, 机器人能够在其抓取器和触觉感应器中获得强力/感应器, 而触觉感应器在涉及接触丰富的运动的任务中往往是必要的。 在这项工作中, 我们利用触摸反馈不匹配的惊喜来引导在硬性微分奖励强化学习任务中的探索。 我们的方法, 触摸基础的好奇心( ToC), 了解什么可见的物体相互作用应该像“ 感觉” 一样。 我们鼓励通过奖励期望和经验不匹配的相互作用来探索。 在我们提议的方法中, 初始任务独立的探索阶段之后, 是一个在任务上学习阶段, 最初的相互作用会与任务上的报酬重新贴上标签。 我们测试我们的方法是一系列触摸密集的机器人手臂任务( 例如, 推动物体, 开启门 ), 我们也在这项工作中释放了这些任务。 在模拟环境中的多重实验中, 我们证明我们的方法能够通过微薄的奖励和好奇心来学习这些困难的任务。 我们比较我们的跨模式方法, 将我们的方法与单一模式( 微或视觉的) 方法比得更高效的方法。