
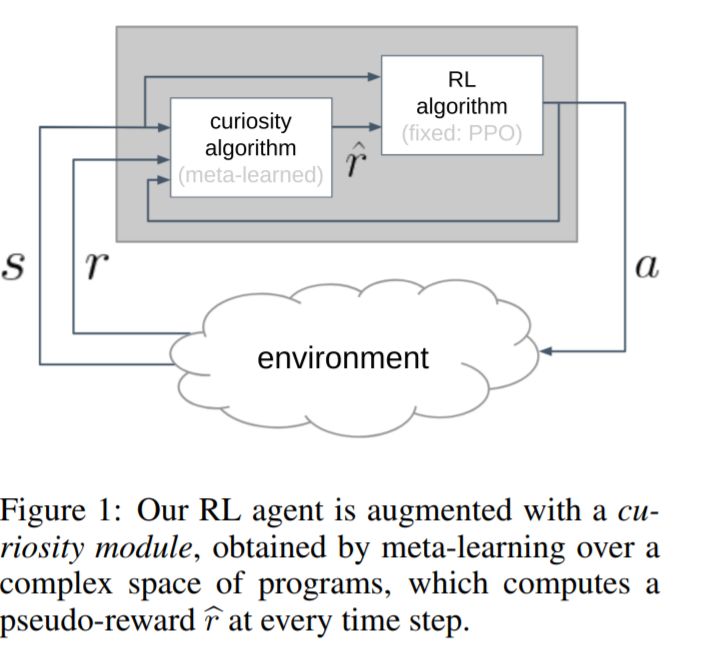
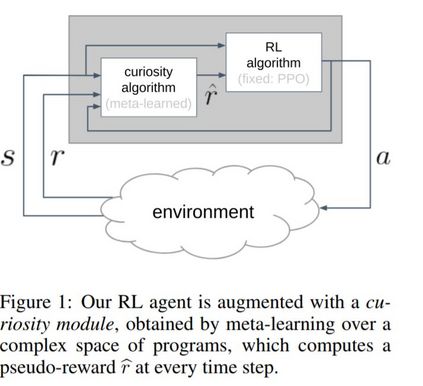
我们假设好奇心是进化过程中发现的一种机制,它鼓励个体在生命早期进行有意义的探索,从而使个体接触到能够在其一生中获得高回报的经历。我们将产生好奇行为的问题表述为元学习的问题之一:一个外环将在一个好奇心机制的空间中搜索,该机制动态地适应代理的奖励信号,而一个内环将使用适应的奖励信号执行标准的强化学习。然而,目前基于神经网络权值传递的meta-RL方法只在非常相似的任务之间进行了推广。为了扩展泛化,我们提出使用元学习算法:类似于ML论文中人类设计的代码片段。我们丰富的程序语言将神经网络与其他构建模块(如缓冲区、最近邻模块和自定义丢失函数)结合在一起。我们通过实验证明了该方法的有效性,发现了两种新的好奇心算法,它们在图像输入网格导航、acrobot、lunar lander、ant和hopper等不同领域的性能与人类设计的公开发布的好奇心算法相当,甚至更好。
成为VIP会员查看完整内容
相关内容
专知会员服务
21+阅读 · 2020年3月28日



相关VIP内容
专知会员服务
21+阅读 · 2020年3月28日
相关资讯