
论文题目
Factorized Multimodal Transformer for Multimodal Sequential Learning
论文简介
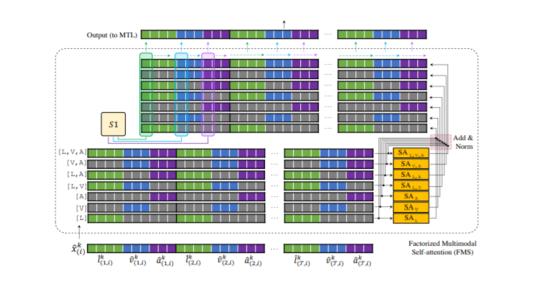
我们周围的复杂世界本质上是多模态和连续的。信息分散在不同的模式中,需要捕获多个连续的传感器。随着机器学习向更好的泛化方向发展,多模态序贯学习成为一个基础研究领域。可以说,在模式内和模式间任意分布的时空动力学建模是这一研究领域的最大挑战。在本文中,我们提出了一个新的变压器模型,称为因子化多模变压器(FMT)的多模顺序学习。FMT以因子分解的方式固有地在其多模态输入中对模式内和多式联运(涉及两个或多个模式)动力学建模。所提出的因子分解允许增加自我关注的数量,以便更好地模拟手边的多模现象;即使在相对较低的资源设置下,在训练期间也不会遇到困难(例如过度拟合)。FMT中的所有注意机制都有一个完整的时域接收场,使它们能够异步捕获远程多模态动力学。在我们的实验中,我们将重点放在包含语言、视觉和听觉三种常用研究模式的数据集上。我们进行了广泛的实验,跨越了3个研究良好的数据集和21个不同的标签。FMT显示出优于先前提出的模型的性能,在研究的数据集中创造了新的技术状态。
论文作者
Amir Zadeh, Chengfeng Mao, Kelly Shi, Yiwei Zhang, Paul Pu Liang, Soujanya Poria, Louis-Philippe Morency,作者们长期从事人工智能研究,是机器学习领域专家级人物,在研究过程中,主张机器学习要面向实践,面向实际,立志解决当前问题,随着机器学习向更好的泛化方向发展,多模态序贯学习成为一个基础研究领域,作者们在该领域进行了大量的资源投入,并取得了丰硕成果。
成为VIP会员查看完整内容
相关内容

专知会员服务
71+阅读 · 2020年2月5日
专知会员服务
85+阅读 · 2020年1月15日
专知会员服务
80+阅读 · 2019年11月5日
Arxiv
4+阅读 · 2020年3月5日
Arxiv
9+阅读 · 2018年5月31日
Arxiv
3+阅读 · 2018年5月1日



相关VIP内容
专知会员服务
71+阅读 · 2020年2月5日
专知会员服务
85+阅读 · 2020年1月15日
专知会员服务
80+阅读 · 2019年11月5日
相关资讯