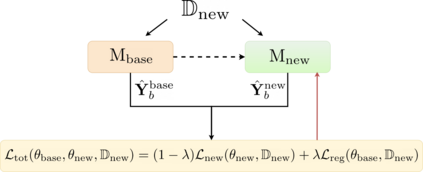
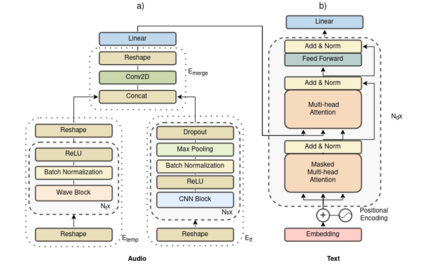
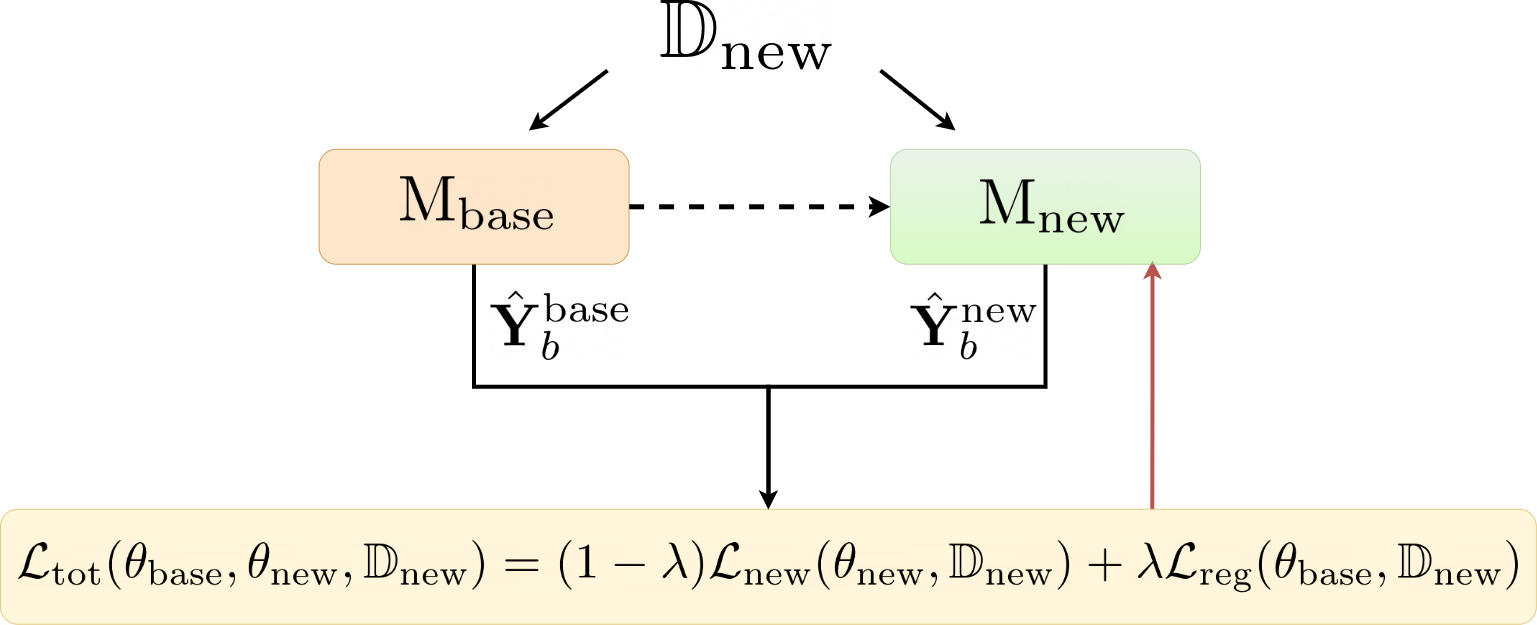
Automated audio captioning (AAC) is the task of automatically creating textual descriptions (i.e. captions) for the contents of a general audio signal. Most AAC methods are using existing datasets to optimize and/or evaluate upon. Given the limited information held by the AAC datasets, it is very likely that AAC methods learn only the information contained in the utilized datasets. In this paper we present a first approach for continuously adapting an AAC method to new information, using a continual learning method. In our scenario, a pre-optimized AAC method is used for some unseen general audio signals and can update its parameters in order to adapt to the new information, given a new reference caption. We evaluate our method using a freely available, pre-optimized AAC method and two freely available AAC datasets. We compare our proposed method with three scenarios, two of training on one of the datasets and evaluating on the other and a third of training on one dataset and fine-tuning on the other. Obtained results show that our method achieves a good balance between distilling new knowledge and not forgetting the previous one.
翻译:自动录音字幕(AAC)是自动为一般音频信号的内容自动创建文字描述(即标题)的任务。大多数AAC方法正在利用现有的数据集优化和/或评估。鉴于AAC数据集所掌握的信息有限,AAC方法极有可能只学习已使用数据集中的信息。在本文中,我们提出一种方法,即利用不断学习的方法,不断使AAC方法适应新信息。在我们的设想中,对一些看不见的一般音频信号采用预先优化的AAC方法,并能够更新其参数,以适应新的信息,并给出新的参考说明。我们使用一种可自由获取的预选AAC方法和两种可自由获取的AAC数据集来评估我们的方法。我们比较了我们拟议的方法与三种假设,即两个关于一个数据集的培训以及对另一个数据集的评估,以及第三个关于一个数据集的培训与对另一个数据集的微调。获得的结果表明,我们的方法在淡化新知识与不忘记以前的知识之间取得了良好的平衡。