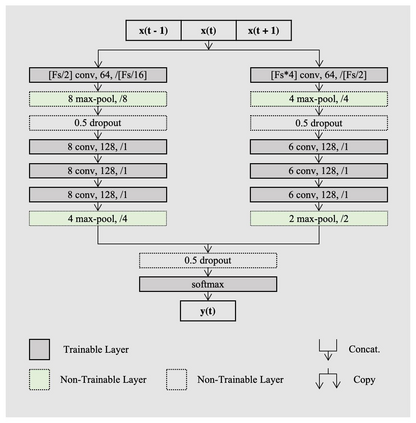
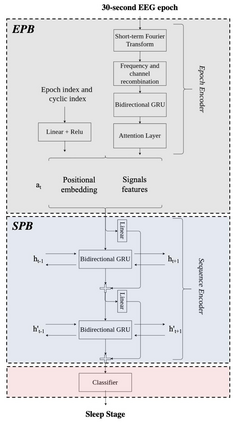
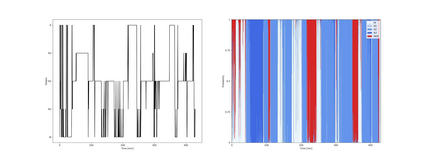
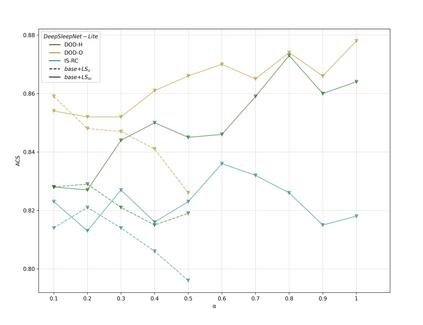
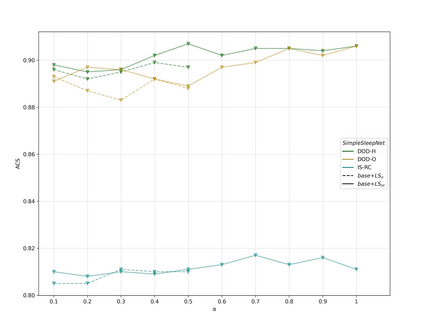
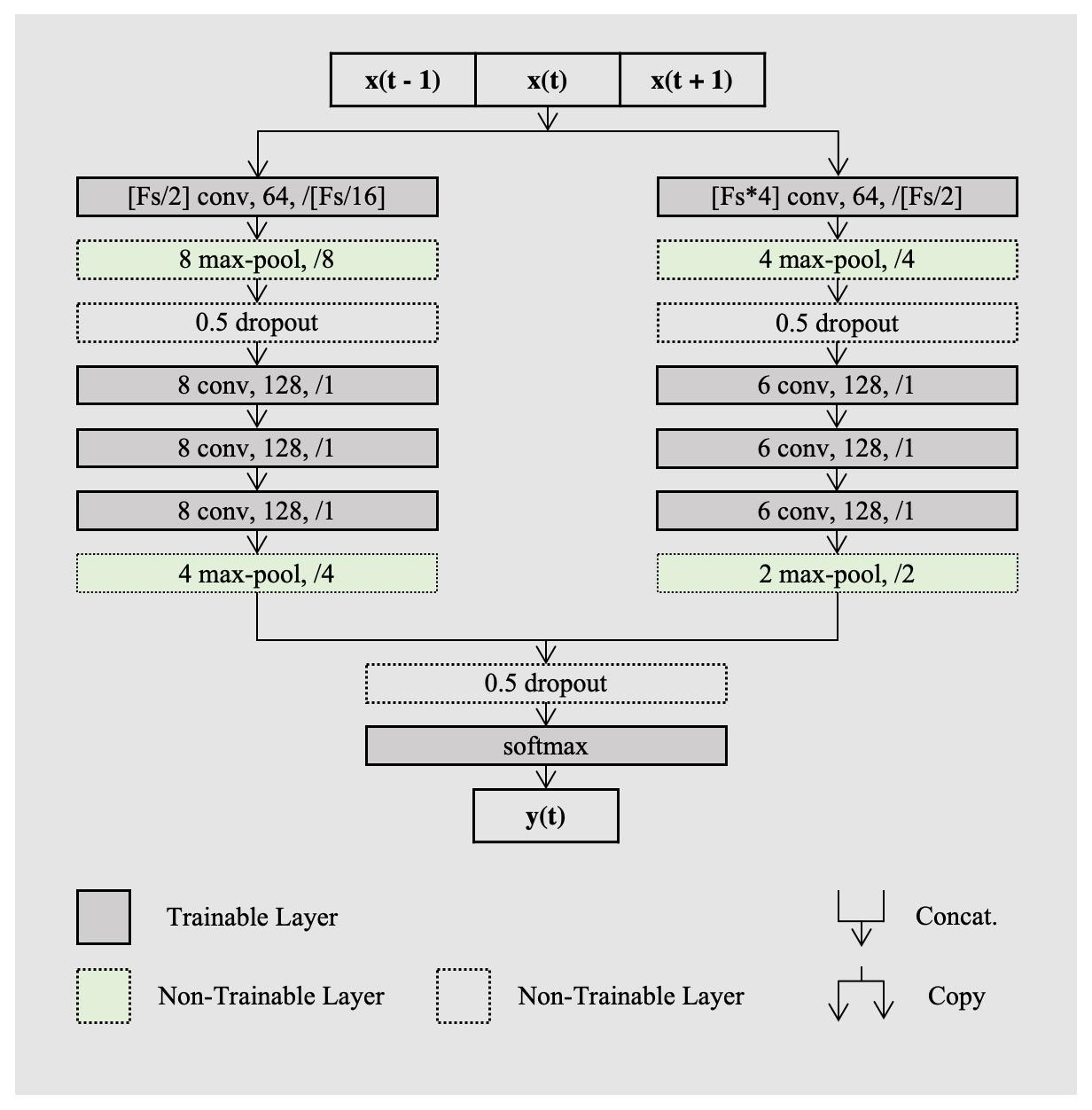
Study Objectives: Inter-scorer variability in scoring polysomnograms is a well-known problem. Most of the existing automated sleep scoring systems are trained using labels annotated by a single scorer, whose subjective evaluation is transferred to the model. When annotations from two or more scorers are available, the scoring models are usually trained on the scorer consensus. The averaged scorer's subjectivity is transferred into the model, losing information about the internal variability among different scorers. In this study, we aim to insert the multiple-knowledge of the different physicians into the training procedure.The goal is to optimize a model training, exploiting the full information that can be extracted from the consensus of a group of scorers. Methods: We train two lightweight deep learning based models on three different multi-scored databases. We exploit the label smoothing technique together with a soft-consensus (LSSC) distribution to insert the multiple-knowledge in the training procedure of the model. We introduce the averaged cosine similarity metric (ACS) to quantify the similarity between the hypnodensity-graph generated by the models with-LSSC and the hypnodensity-graph generated by the scorer consensus. Results: The performance of the models improves on all the databases when we train the models with our LSSC. We found an increase in ACS (up to 6.4%) between the hypnodensity-graph generated by the models trained with-LSSC and the hypnodensity-graph generated by the consensus. Conclusions: Our approach definitely enables a model to better adapt to the consensus of the group of scorers. Future work will focus on further investigations on different scoring architectures.
翻译:研究目标: 评分多索美图中的分数差异是一个众所周知的问题。 现有的多数自动睡眠评分系统都是使用由单一得分者加注的标签培训的, 该得分者的主观评价被转移到模型中。 当有来自两个或两个以上得分者的说明时, 评分模型通常会根据得分者的共识进行培训。 平均得分者的主观性被转移到模型中, 不同得分者之间的内部变数信息会丢失。 在此研究中, 我们的目标是在培训程序中插入不同医生的多重认知。 目标是优化模型培训, 利用从一组得分者共识中提取的完整信息。 方法 : 我们用三个不同的多分数数据库来培训两个轻度深度学习模型。 我们利用标签和软一致( LSSC) 分布来将多种知识插入模型的培训程序中。 我们通过经过培训的CSB(ACS) 将测算的测算方法( ACS) 用于进一步量化模型的类似性( ) 。 由模型生成的精度- mexbalbisal 和我们所有的测算结果数据库中, 将产生我们所有得分数模型的测算结果数据库中, 。 将我们所测得的测算结果的测得的测算结果的测算结果将使我们的测算为CMS- h。