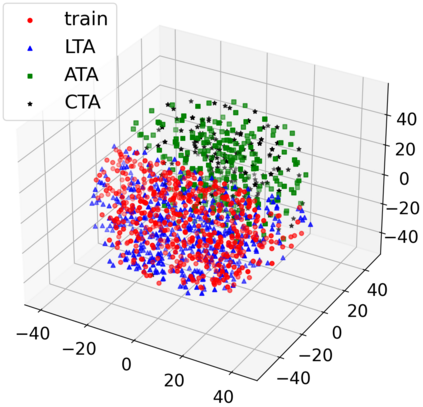
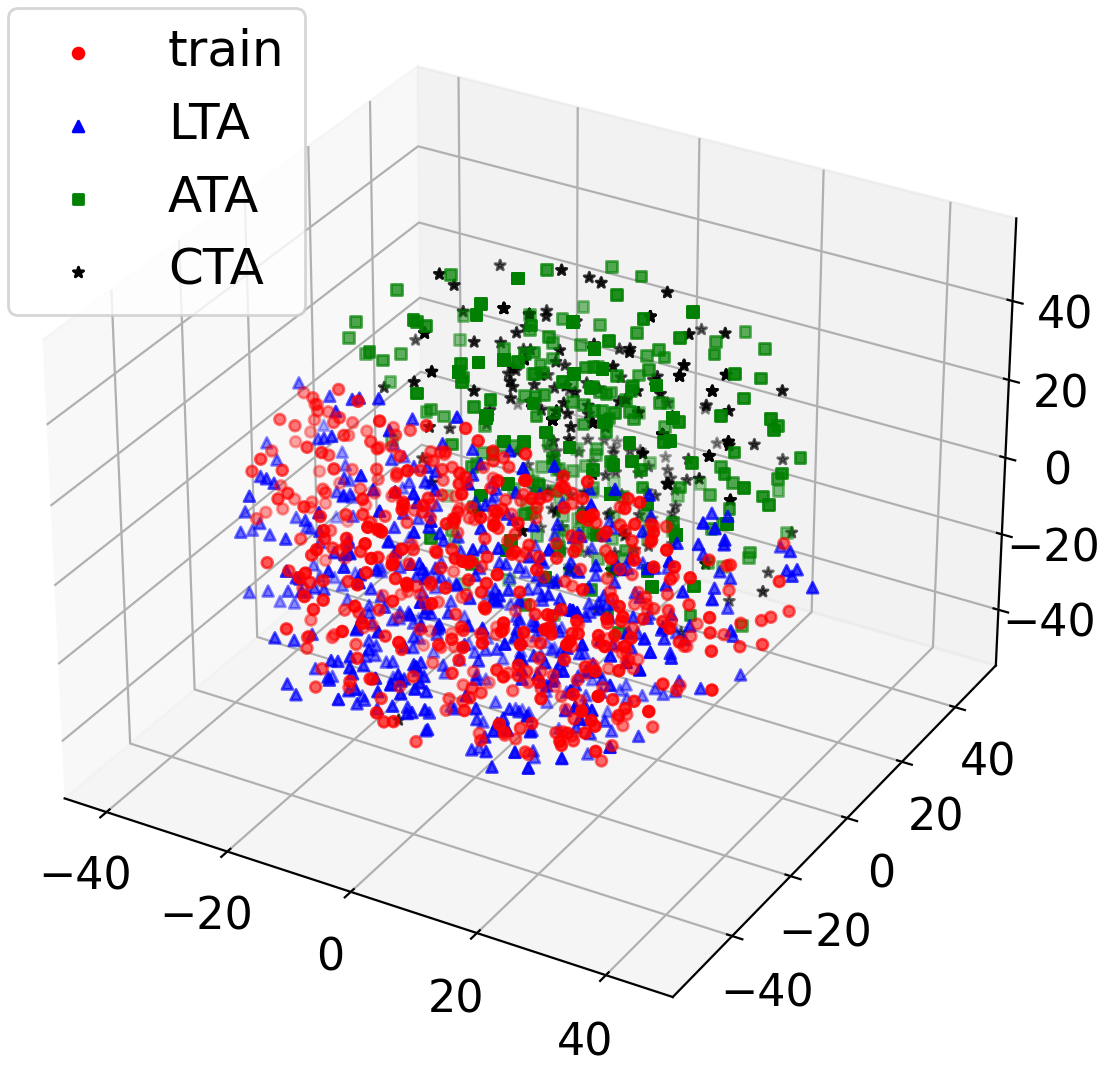
Dialogue understanding tasks often necessitate abundant annotated data to achieve good performance and that presents challenges in low-resource settings. To alleviate this barrier, we explore few-shot data augmentation for dialogue understanding by prompting large pre-trained language models and present a novel approach that iterates on augmentation quality by applying weakly-supervised filters. We evaluate our methods on the emotion and act classification tasks in DailyDialog and the intent classification task in Facebook Multilingual Task-Oriented Dialogue. Models fine-tuned on our augmented data mixed with few-shot ground truth data are able to approach or surpass existing state-of-the-art performance on both datasets. For DailyDialog specifically, using 10% of the ground truth data we outperform the current state-of-the-art model which uses 100% of the data.
翻译:对话理解任务往往需要大量附加说明的数据才能取得良好的业绩,这在低资源环境中也提出了挑战。为了缓解这一障碍,我们探索了微小的数据增强,通过推广大型的预先培训语言模型来加深对话理解,并提出了一种新颖的方法,通过应用薄弱的监管过滤器来反复提升质量。我们评估了我们在DailyDialog中的情感和行动分类任务的方法,以及Facebook多语言任务对话中的意向分类任务。对与微小地面真相数据混合的扩大数据进行微调的模型能够接近或超过两个数据集的现有最新性能。对于DailyDialog来说,具体来说,我们使用10%的地面真相数据,我们比目前使用100%数据的最先进的模型要高得多。