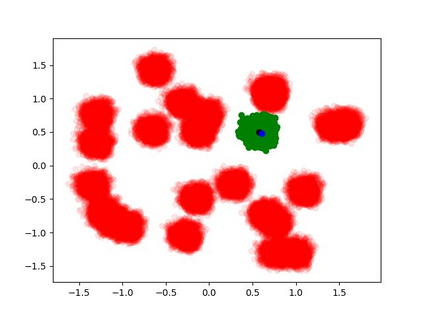
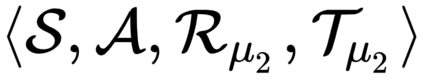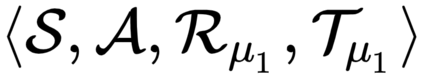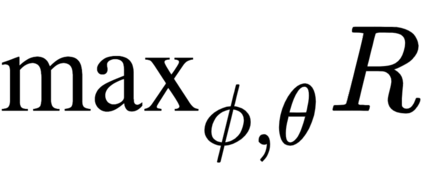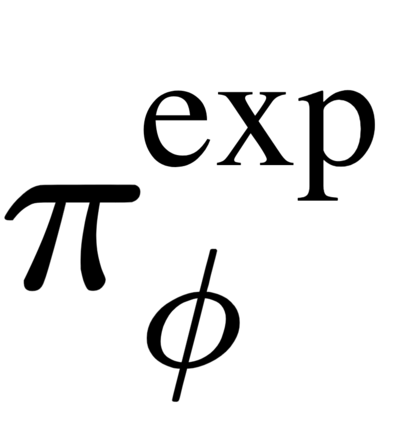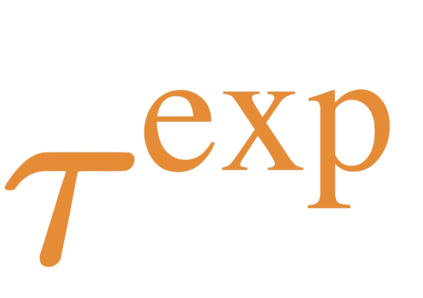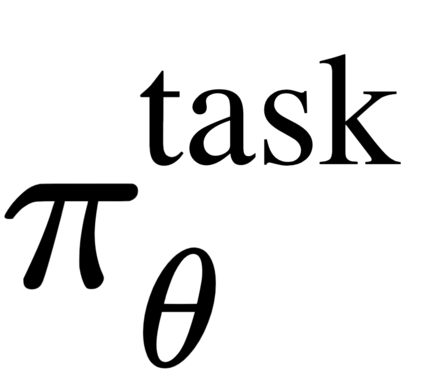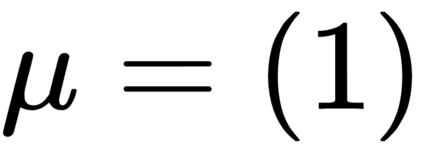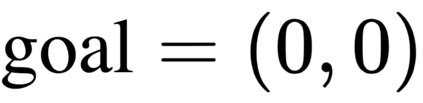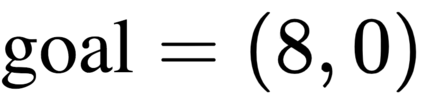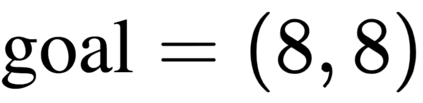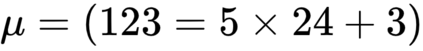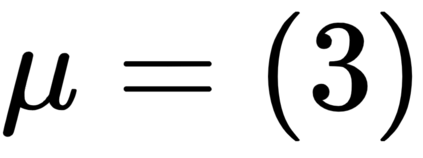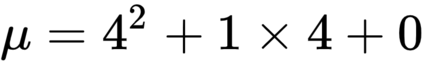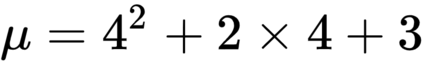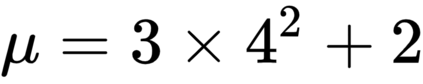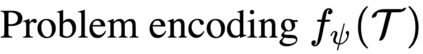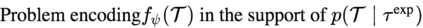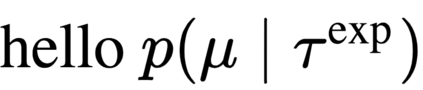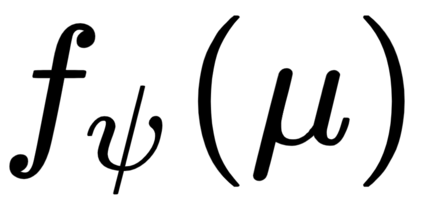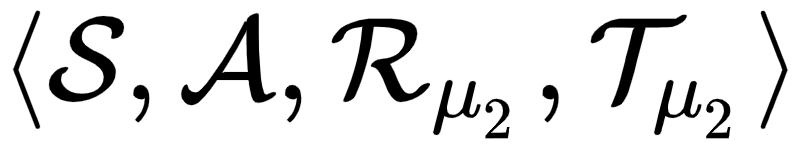The goal of meta-reinforcement learning (meta-RL) is to build agents that can quickly learn new tasks by leveraging prior experience on related tasks. Learning a new task often requires both exploring to gather task-relevant information and exploiting this information to solve the task. In principle, optimal exploration and exploitation can be learned end-to-end by simply maximizing task performance. However, such meta-RL approaches struggle with local optima due to a chicken-and-egg problem: learning to explore requires good exploitation to gauge the exploration's utility, but learning to exploit requires information gathered via exploration. Optimizing separate objectives for exploration and exploitation can avoid this problem, but prior meta-RL exploration objectives yield suboptimal policies that gather information irrelevant to the task. We alleviate both concerns by constructing an exploitation objective that automatically identifies task-relevant information and an exploration objective to recover only this information. This avoids local optima in end-to-end training, without sacrificing optimal exploration. Empirically, DREAM substantially outperforms existing approaches on complex meta-RL problems, such as sparse-reward 3D visual navigation. Videos of DREAM: https://ezliu.github.io/dream/
翻译:元加强学习(meta-RL)的目标是培养能够通过利用先前相关任务的经验迅速学习新任务的代理商,从而能够通过利用相关任务的经验迅速学习新任务。学习新任务往往需要探索以收集与任务相关的信息和利用这一信息来完成任务。原则上,最佳勘探和开发可以通过仅仅最大限度地提高任务绩效来学习端到端。然而,由于鸡和鸡的问题,这类元加强学习方法与本地选择系统(meta-RL)相争:学习探索需要良好的利用,以衡量勘探的效用,但学习开发需要通过勘探收集的信息。优化勘探和开发的不同目标可以避免这一问题,但先前的元加强探索目标可以产生收集与任务无关信息的亚优政策。我们通过建立自动确定任务相关信息的开发目标以及仅恢复这些信息的探索目标来缓解这两种关切。这避免了终端到端培训中的本地选择,同时不牺牲最佳勘探。Empirical,DREAM实质上超越了目前对复杂的元-RL问题采取的方法,例如:Slow-reward 3Dlioview.DAMs Damams。