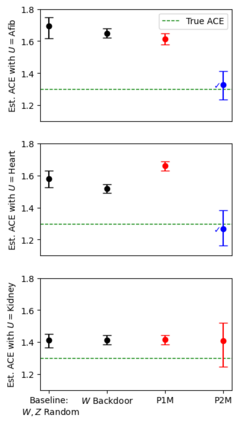
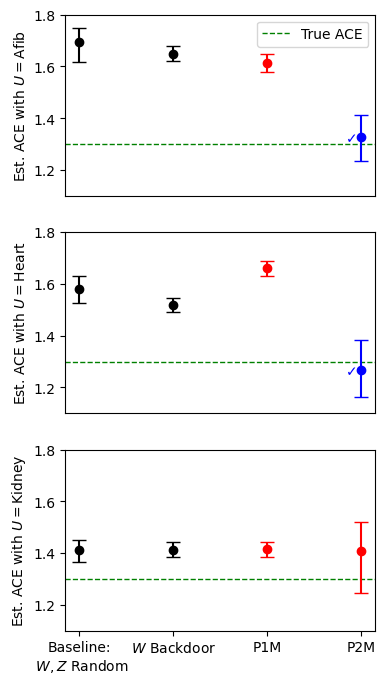
Recent text-based causal methods attempt to mitigate confounding bias by including unstructured text data as proxies of confounding variables that are partially or imperfectly measured. These approaches assume analysts have supervised labels of the confounders given text for a subset of instances, a constraint that is not always feasible due to data privacy or cost. Here, we address settings in which an important confounding variable is completely unobserved. We propose a new causal inference method that splits pre-treatment text data, infers two proxies from two zero-shot models on the separate splits, and applies these proxies in the proximal g-formula. We prove that our text-based proxy method satisfies identification conditions required by the proximal g-formula while other seemingly reasonable proposals do not. We evaluate our method in synthetic and semi-synthetic settings and find that it produces estimates with low bias. This combination of proximal causal inference and zero-shot classifiers is novel (to our knowledge) and expands the set of text-specific causal methods available to practitioners.
翻译:暂无翻译