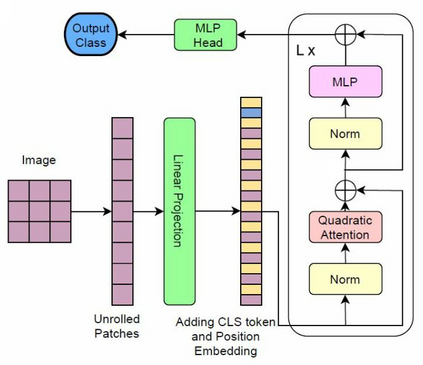
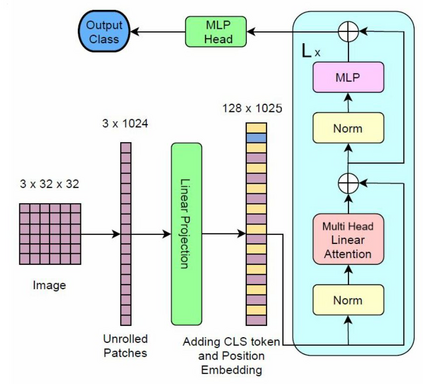
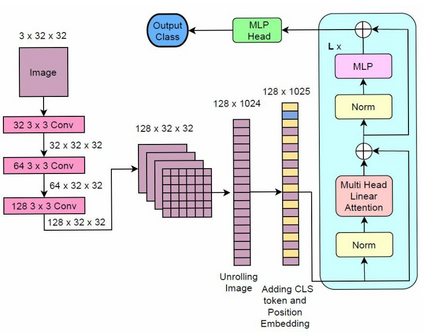
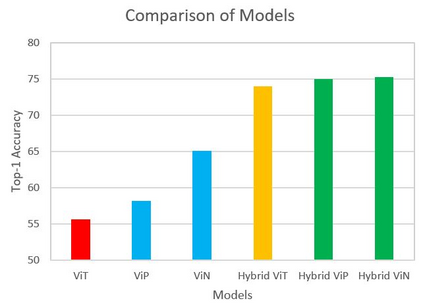
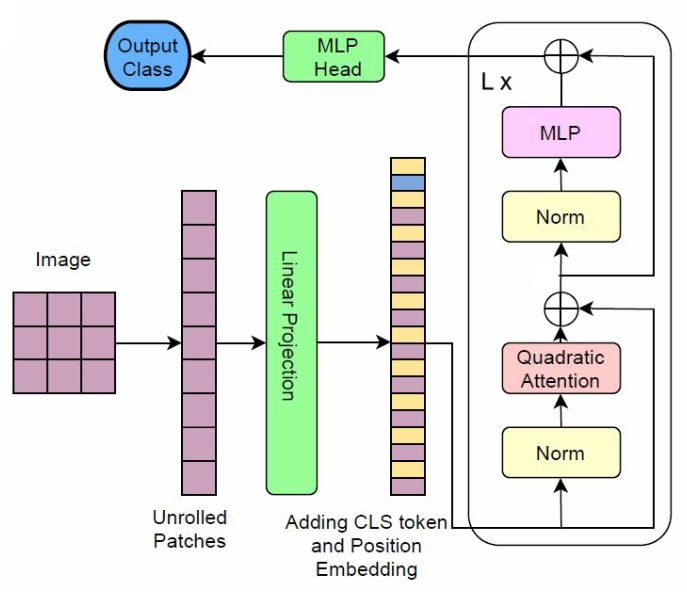
We propose three improvements to vision transformers (ViT) to reduce the number of trainable parameters without compromising classification accuracy. We address two shortcomings of the early ViT architectures -- quadratic bottleneck of the attention mechanism and the lack of an inductive bias in their architectures that rely on unrolling the two-dimensional image structure. Linear attention mechanisms overcome the bottleneck of quadratic complexity, which restricts application of transformer models in vision tasks. We modify the ViT architecture to work on longer sequence data by replacing the quadratic attention with efficient transformers, such as Performer, Linformer and Nystr\"omformer of linear complexity creating Vision X-formers (ViX). We show that all three versions of ViX may be more accurate than ViT for image classification while using far fewer parameters and computational resources. We also compare their performance with FNet and multi-layer perceptron (MLP) mixer. We further show that replacing the initial linear embedding layer by convolutional layers in ViX further increases their performance. Furthermore, our tests on recent vision transformer models, such as LeViT, Convolutional vision Transformer (CvT), Compact Convolutional Transformer (CCT) and Pooling-based Vision Transformer (PiT) show that replacing the attention with Nystr\"omformer or Performer saves GPU usage and memory without deteriorating the classification accuracy. We also show that replacing the standard learnable 1D position embeddings in ViT with Rotary Position Embedding (RoPE) give further improvements in accuracy. Incorporating these changes can democratize transformers by making them accessible to those with limited data and computing resources.
翻译:我们建议对视觉变压器(ViT)进行三项改进,以减少可训练参数的数量,同时又不降低分类准确性。我们解决了早期ViT结构的两个缺陷 -- -- 关注机制的四角瓶颈,以及其结构中缺乏依赖二维图像结构开动的感化偏差。线性关注机制克服了四面性复杂性的瓶颈,这限制了变压模型在视觉任务中的应用。我们修改ViT结构,使其在较长序列数据上发挥作用,以高效的变压器取代二次式关注,例如表现器、Linexter和Nystr\"线性复杂线性变压变压器等。此外,我们测试最近的视觉变压模型,如变压变压的变压器、变压式变压的变压器、变压的变压器、变压的变压的变压器、变压的变压的变压器、变压的变压的变压器、变压的变压的变压器、变压的变压的变压式、变压的变压的变压、变压的变压的变压的变换、变压的变压的变压的变换、变压的变压的变压的变换、变换的变压的变压的变换的变压的变换的变换的变换的变换的变换的变换的变换的变换的变换、变换、变换的变的变的变换的变换的变换的变换的变换的变的变换的变换的变换的变换的变换的变换的变换的变换的变换的变换的变换的变换的变换的变换的变换的变式、变换的变换的变换的变换的变换的变换的变换的变式、变式、变式、变式、变式、变的变的变换的变式、变换的变换的变换的变换的变换的变换的变换的变换的变式、变的变式、变的变的变式、变换的变式、变式、变式、变换的变式、变式、变式、变式、变换的变换的