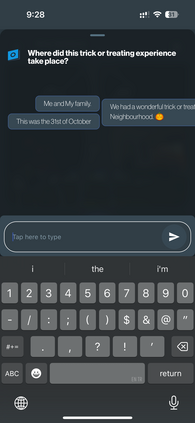
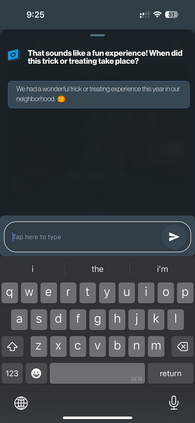
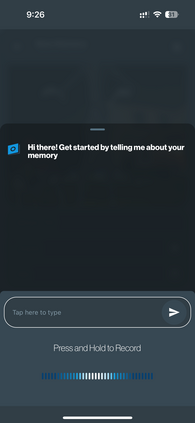
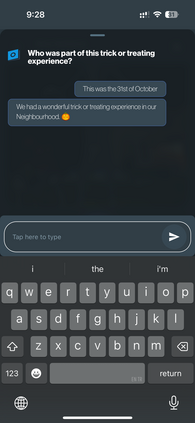
Retrieval-Augmented Generation (RAG) is one of the leading and most widely used techniques for enhancing LLM retrieval capabilities, but it still faces significant limitations in commercial use cases. RAG primarily relies on the query-chunk text-to-text similarity in the embedding space for retrieval and can fail to capture deeper semantic relationships across chunks, is highly sensitive to chunking strategies, and is prone to hallucinations. To address these challenges, we propose TOBUGraph, a graph-based retrieval framework that first constructs the knowledge graph from unstructured data dynamically and automatically. Using LLMs, TOBUGraph extracts structured knowledge and diverse relationships among data, going beyond RAG's text-to-text similarity. Retrieval is achieved through graph traversal, leveraging the extracted relationships and structures to enhance retrieval accuracy, eliminating the need for chunking configurations while reducing hallucination. We demonstrate TOBUGraph's effectiveness in TOBU, a real-world application in production for personal memory organization and retrieval. Our evaluation using real user data demonstrates that TOBUGraph outperforms multiple RAG implementations in both precision and recall, significantly improving user experience through improved retrieval accuracy.
翻译:暂无翻译