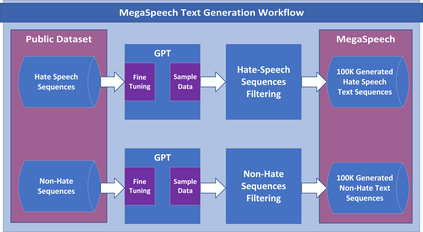
Automatic hate speech detection using deep neural models is hampered by the scarcity of labeled datasets, leading to poor generalization. To mitigate this problem, generative AI has been utilized to generate large amounts of synthetic hate speech sequences from available labeled examples, leveraging the generated data in finetuning large pre-trained language models (LLMs). In this chapter, we provide a review of relevant methods, experimental setups and evaluation of this approach. In addition to general LLMs, such as BERT, RoBERTa and ALBERT, we apply and evaluate the impact of train set augmentation with generated data using LLMs that have been already adapted for hate detection, including RoBERTa-Toxicity, HateBERT, HateXplain, ToxDect, and ToxiGen. An empirical study corroborates our previous findings, showing that this approach improves hate speech generalization, boosting recall performance across data distributions. In addition, we explore and compare the performance of the finetuned LLMs with zero-shot hate detection using a GPT-3.5 model. Our results demonstrate that while better generalization is achieved using the GPT-3.5 model, it achieves mediocre recall and low precision on most datasets. It is an open question whether the sensitivity of models such as GPT-3.5, and onward, can be improved using similar techniques of text generation.
翻译:暂无翻译