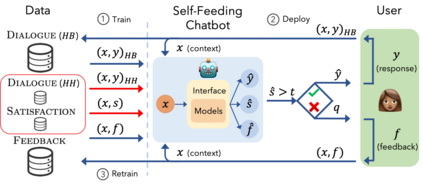
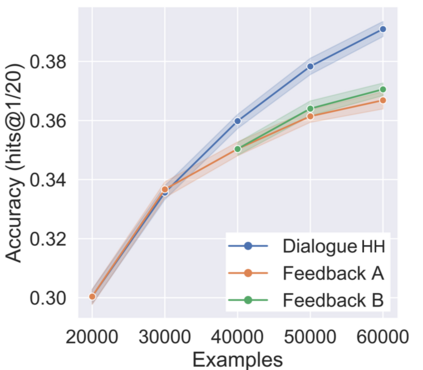
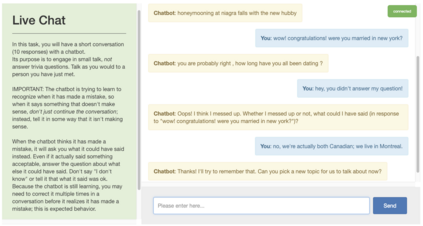
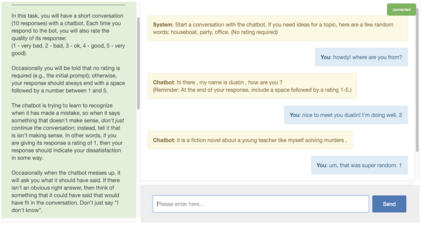
The majority of conversations a dialogue agent sees over its lifetime occur after it has already been trained and deployed, leaving a vast store of potential training signal untapped. In this work, we propose the self-feeding chatbot, a dialogue agent with the ability to extract new training examples from the conversations it participates in. As our agent engages in conversation, it also estimates user satisfaction in its responses. When the conversation appears to be going well, the user's responses become new training examples to imitate. When the agent believes it has made a mistake, it asks for feedback; learning to predict the feedback that will be given improves the chatbot's dialogue abilities further. On the PersonaChat chit-chat dataset with over 131k training examples, we find that learning from dialogue with a self-feeding chatbot significantly improves performance, regardless of the amount of traditional supervision.
翻译:大部分对话代理器在经过培训和部署后看到其存在寿命的谈话,留下大量潜在的培训信号。 在这项工作中,我们推荐了能够从其参与的谈话中提取新的培训实例的对话代理器,即自食其力的聊天机。随着我们的代理器参与对话,它也估计用户对其答复的满意度。当谈话似乎进展顺利时,用户的回复成为模仿的新培训范例。当该代理器认为自己犯了错误时,它要求提供反馈;学习预测将提供的反馈,进一步提高了聊天机的对话能力。在PrimanaChat chit聊天数据集中,有超过131k个培训实例,我们发现从与自食用聊天机的对话中学习会大大改善业绩,而不管传统监督的程度如何。