
As massive medical data become available with an increasing number of scans, expanding classes, and varying sources, prevalent training paradigms -- where AI is trained with multiple passes over fixed, finite datasets -- face significant challenges. First, training AI all at once on such massive data is impractical as new scans/sources/classes continuously arrive. Second, training AI continuously on new scans/sources/classes can lead to catastrophic forgetting, where AI forgets old data as it learns new data, and vice versa. To address these two challenges, we propose an online learning method that enables training AI from massive medical data. Instead of repeatedly training AI on randomly selected data samples, our method identifies the most significant samples for the current AI model based on their data uniqueness and prediction uncertainty, then trains the AI on these selective data samples. Compared with prevalent training paradigms, our method not only improves data efficiency by enabling training on continual data streams, but also mitigates catastrophic forgetting by selectively training AI on significant data samples that might otherwise be forgotten, outperforming by 15% in Dice score for multi-organ and tumor segmentation. The code is available at https://github.com/MrGiovanni/OnlineLearning
翻译:暂无翻译
























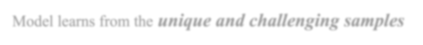


















相关内容

Source: Apple - iOS 8

