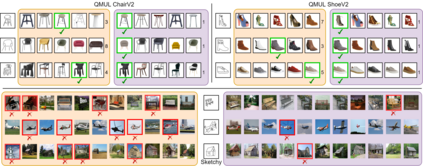
Sketch-based image retrieval (SBIR) is a cross-modal matching problem which is typically solved by learning a joint embedding space where the semantic content shared between photo and sketch modalities are preserved. However, a fundamental challenge in SBIR has been largely ignored so far, that is, sketches are drawn by humans and considerable style variations exist amongst different users. An effective SBIR model needs to explicitly account for this style diversity, crucially, to generalise to unseen user styles. To this end, a novel style-agnostic SBIR model is proposed. Different from existing models, a cross-modal variational autoencoder (VAE) is employed to explicitly disentangle each sketch into a semantic content part shared with the corresponding photo, and a style part unique to the sketcher. Importantly, to make our model dynamically adaptable to any unseen user styles, we propose to meta-train our cross-modal VAE by adding two style-adaptive components: a set of feature transformation layers to its encoder and a regulariser to the disentangled semantic content latent code. With this meta-learning framework, our model can not only disentangle the cross-modal shared semantic content for SBIR, but can adapt the disentanglement to any unseen user style as well, making the SBIR model truly style-agnostic. Extensive experiments show that our style-agnostic model yields state-of-the-art performance for both category-level and instance-level SBIR.
翻译:基于 sclet 的图像检索( SIR) 是一个跨模式的匹配问题, 通常通过学习一个共同嵌入空间来解决, 该空间是照片和素描模式之间共享的语义内容得以保存的。 然而, SBIR 中的一个基本挑战迄今为止基本上被忽视, 即素描是由人类绘制的, 不同用户之间也存在相当的风格差异。 一个有效的 SBIR 模型需要明确解释这种风格的多样性, 关键是, 向隐性用户风格概括化。 为此, 提议了一个创新的风格- 不可调和的 SBIR 模型。 与现有模型不同, 一个跨模式的变异自动调器( VAE ) 用于将每幅素描切内容明确分解成一个与对应图片共享的语义内容部分, 也就是素描缩略图, 使我们的模型能动地适应任何看不见的用户风格, 我们提议将跨模式的VAEEE( ) 引入两个样式适应型式的模块化结构转换层。 将一个固定的图像转换为不折叠式风格, 我们的模型样式的版本的版本的版本的版本的版本的版本的版本, 的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本, 的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的版本的