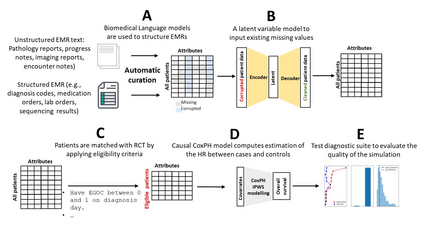
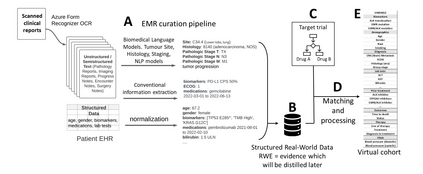
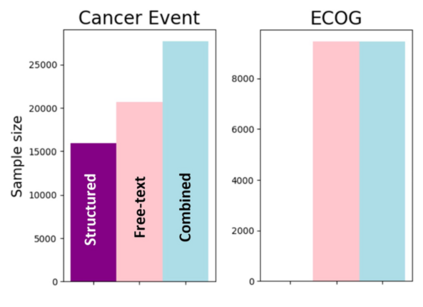
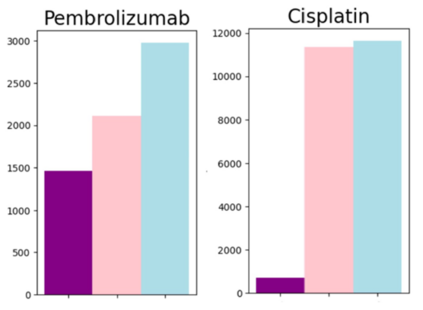
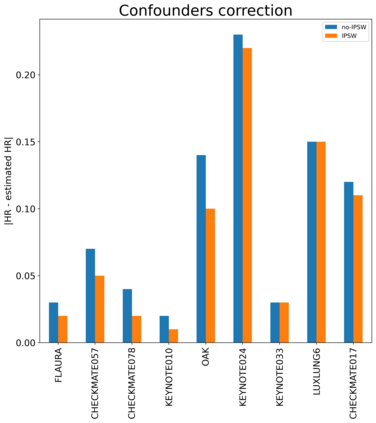
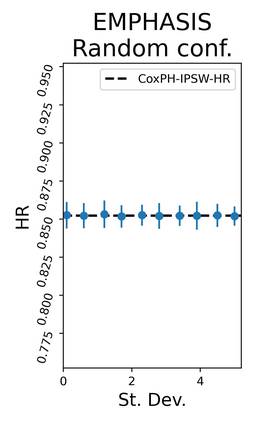
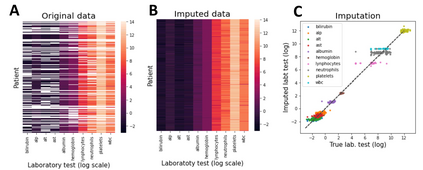
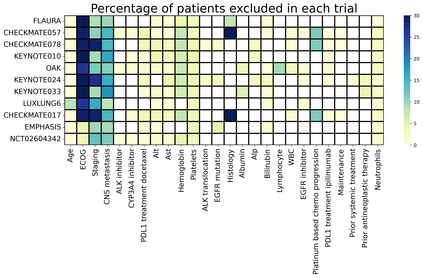
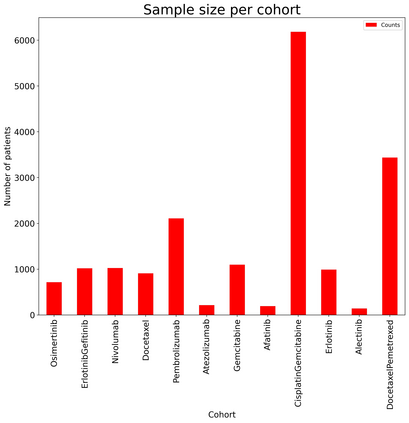
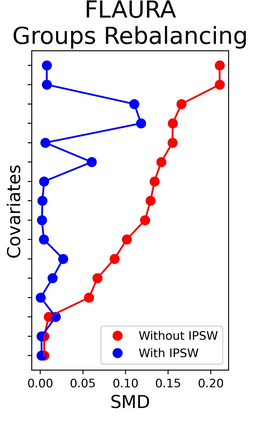
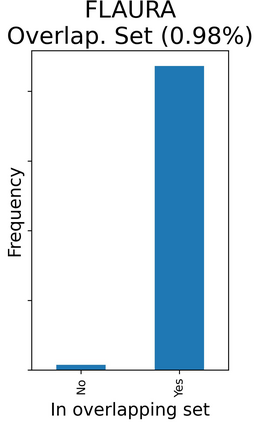
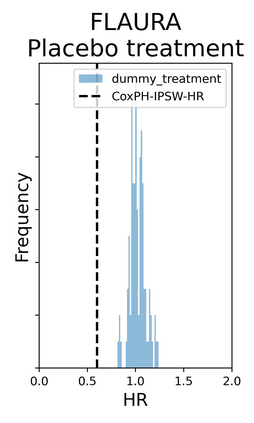
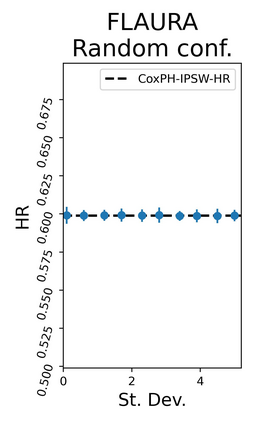
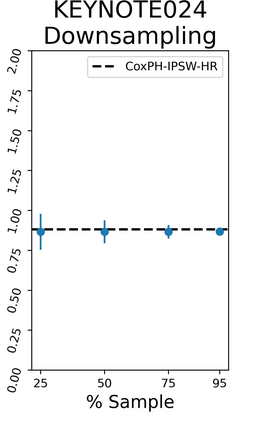
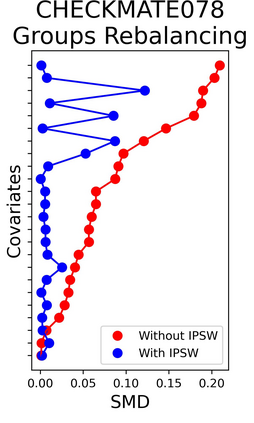
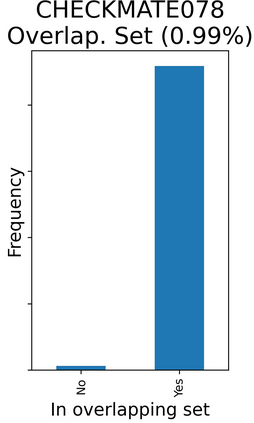
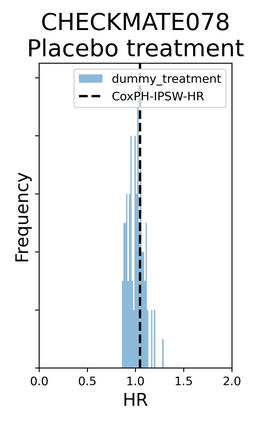
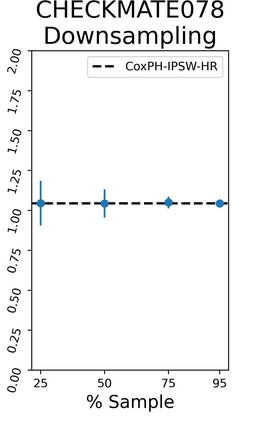
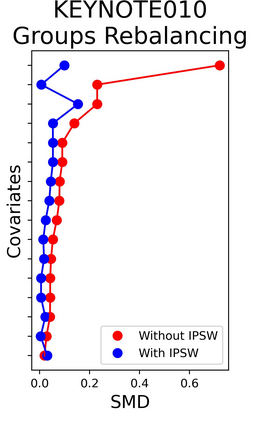
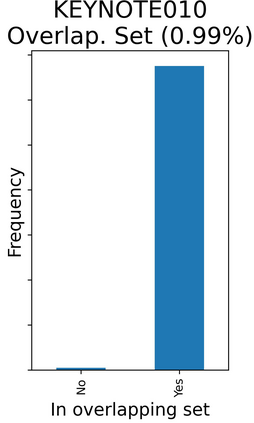
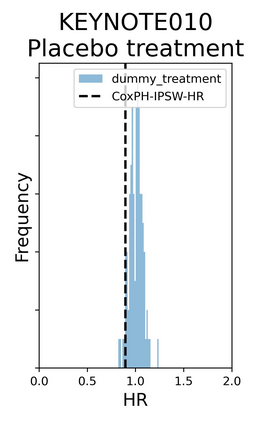
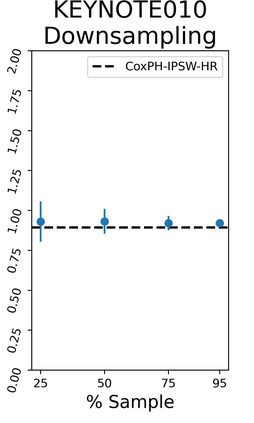
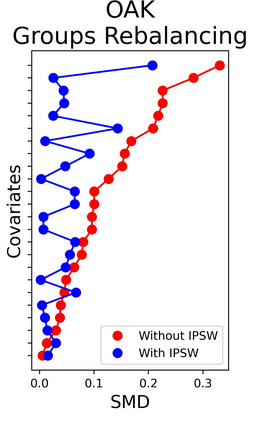
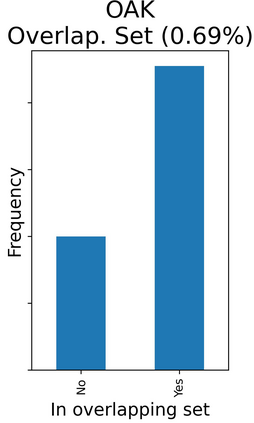
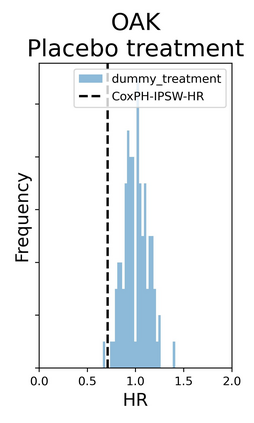
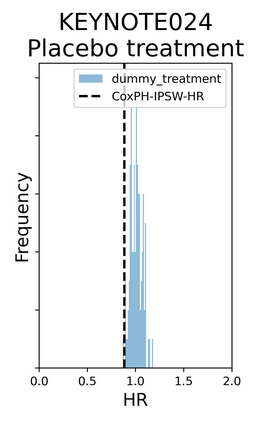
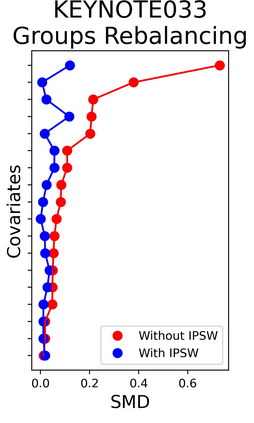
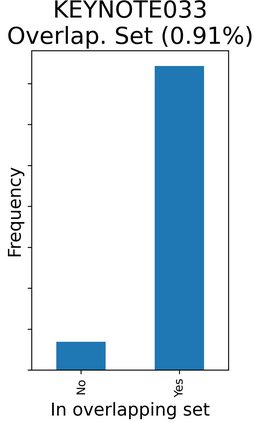
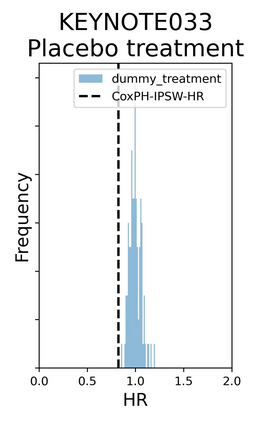
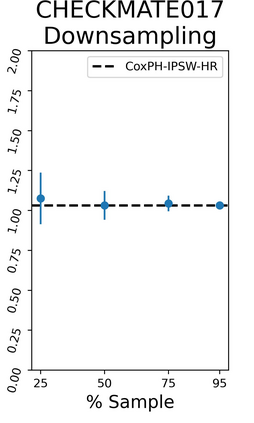
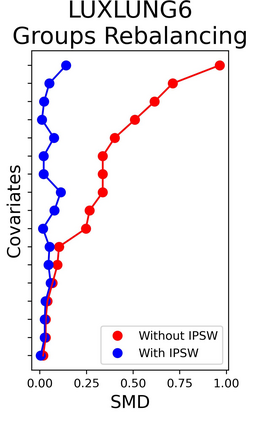
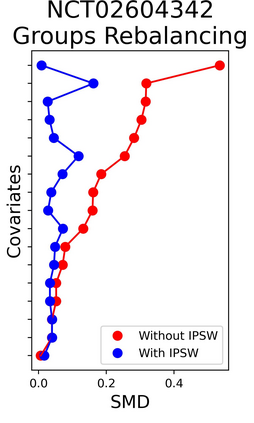
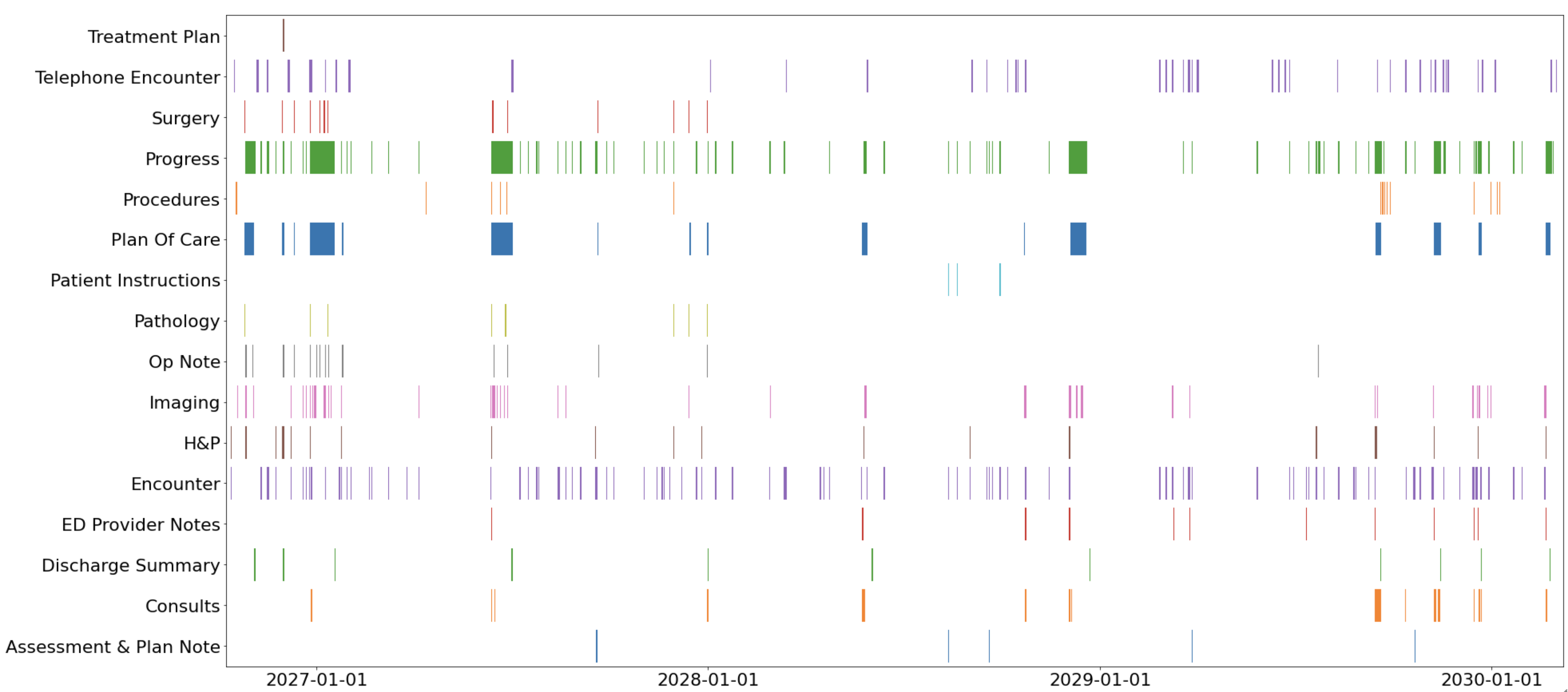
The rapid digitization of real-world data offers an unprecedented opportunity for optimizing healthcare delivery and accelerating biomedical discovery. In practice, however, such data is most abundantly available in unstructured forms, such as clinical notes in electronic medical records (EMRs), and it is generally plagued by confounders. In this paper, we present TRIALSCOPE, a unifying framework for distilling real-world evidence from population-level observational data. TRIALSCOPE leverages biomedical language models to structure clinical text at scale, employs advanced probabilistic modeling for denoising and imputation, and incorporates state-of-the-art causal inference techniques to combat common confounders. Using clinical trial specification as generic representation, TRIALSCOPE provides a turn-key solution to generate and reason with clinical hypotheses using observational data. In extensive experiments and analyses on a large-scale real-world dataset with over one million cancer patients from a large US healthcare network, we show that TRIALSCOPE can produce high-quality structuring of real-world data and generates comparable results to marquee cancer trials. In addition to facilitating in-silicon clinical trial design and optimization, TRIALSCOPE may be used to empower synthetic controls, pragmatic trials, post-market surveillance, as well as support fine-grained patient-like-me reasoning in precision diagnosis and treatment.
翻译:暂无翻译