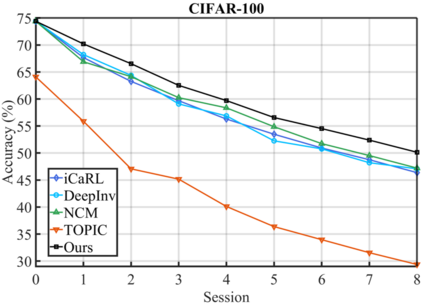
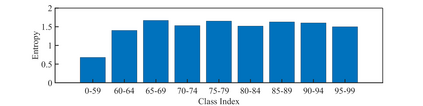
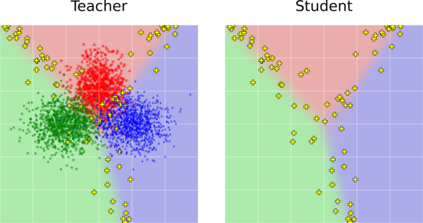
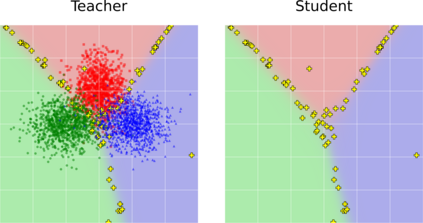
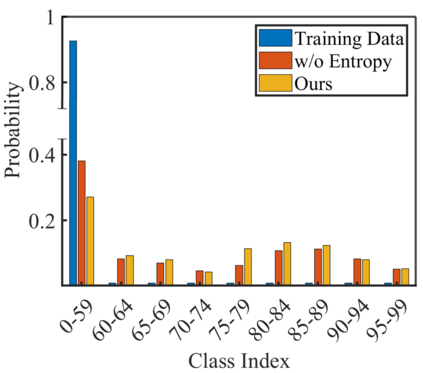
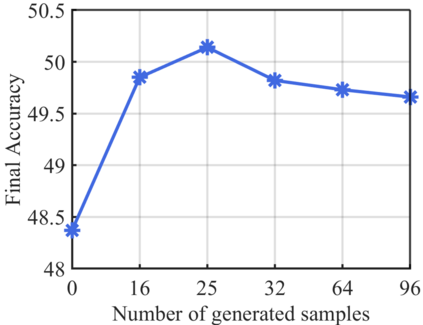
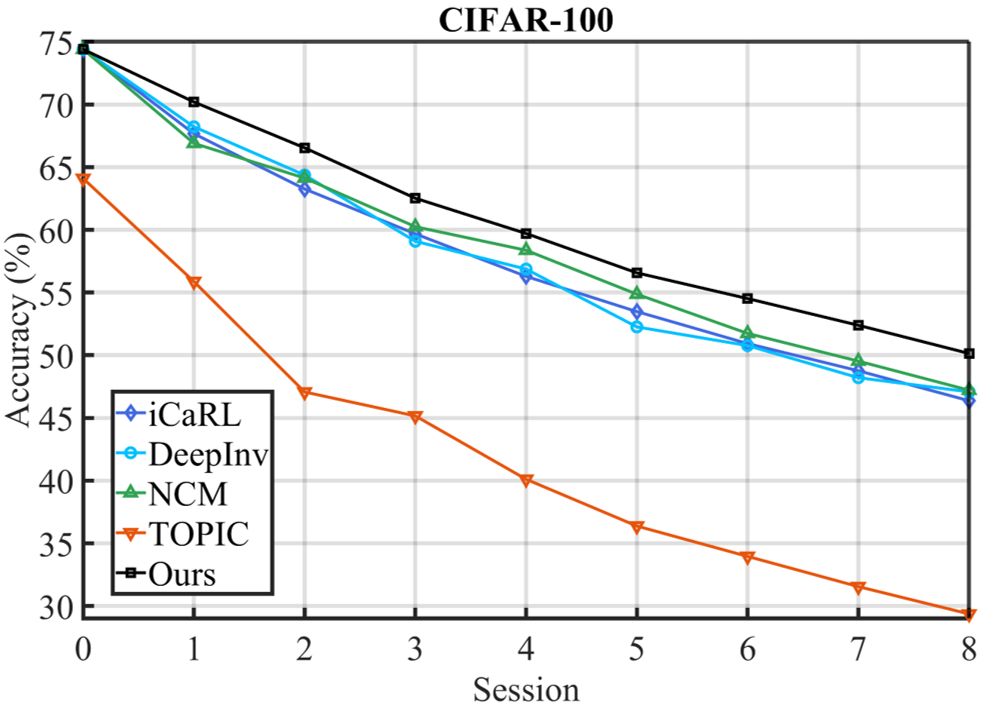
Few-shot class-incremental learning (FSCIL) has been proposed aiming to enable a deep learning system to incrementally learn new classes with limited data. Recently, a pioneer claims that the commonly used replay-based method in class-incremental learning (CIL) is ineffective and thus not preferred for FSCIL. This has, if truth, a significant influence on the fields of FSCIL. In this paper, we show through empirical results that adopting the data replay is surprisingly favorable. However, storing and replaying old data can lead to a privacy concern. To address this issue, we alternatively propose using data-free replay that can synthesize data by a generator without accessing real data. In observing the the effectiveness of uncertain data for knowledge distillation, we impose entropy regularization in the generator training to encourage more uncertain examples. Moreover, we propose to relabel the generated data with one-hot-like labels. This modification allows the network to learn by solely minimizing the cross-entropy loss, which mitigates the problem of balancing different objectives in the conventional knowledge distillation approach. Finally, we show extensive experimental results and analysis on CIFAR-100, miniImageNet and CUB-200 to demonstrate the effectiveness of our proposed one.
翻译:略微少见的课堂强化学习(FSCIL)已经提出,目的是让一个深层次的学习系统能够以有限的数据逐步学习新班级。最近,一位先驱者声称,在课堂强化学习中常用的重放法(CIL)没有效力,因此对于FSCIL来说并不可取。如果真理的话,这对FSCIL领域有重大影响。在本文中,我们通过经验结果显示,采用数据重播是令人惊讶的有利。然而,存储和重播旧数据可能导致隐私问题。为解决这一问题,我们建议使用无数据重放,使一个生成者可以在不获取真实数据的情况下合成数据。在观察知识蒸馏的不确定数据的有效性时,我们在生成者培训中设置了恒星正规化,以鼓励更多不确定的例子。此外,我们提议用一个类似标签将生成的数据重新贴上标签。这一修改使网络得以学习,仅通过尽可能减少交叉性损失,从而减轻常规知识蒸馏方法中不同目标之间的问题。 最后,我们展示了广泛的实验性结果,并分析了我们提议的CFAR1200。