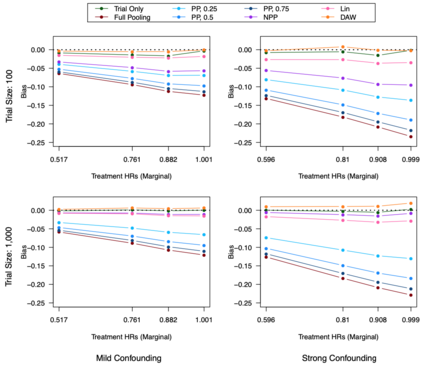
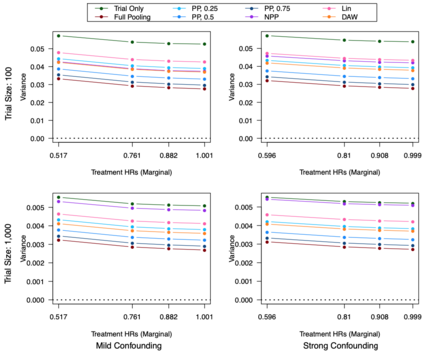
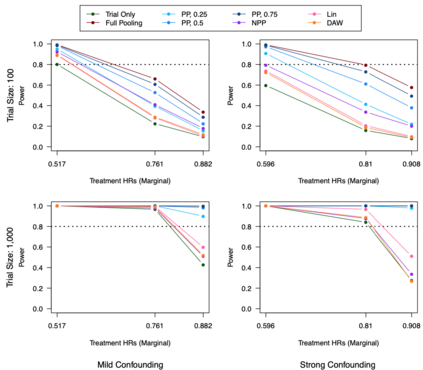
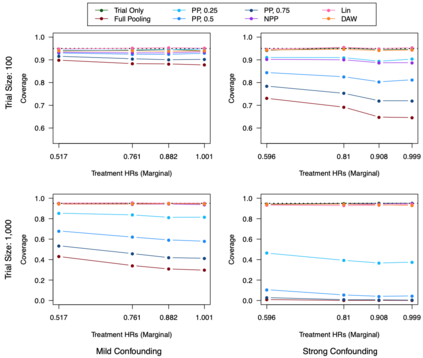
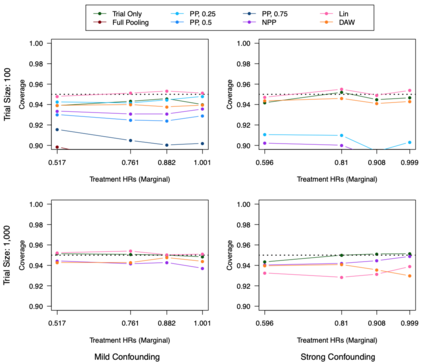
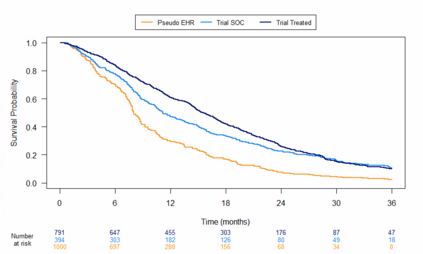
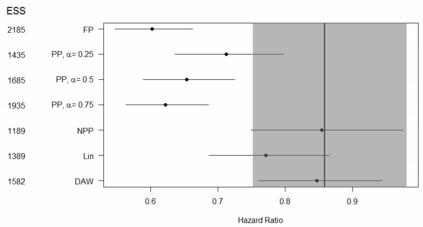
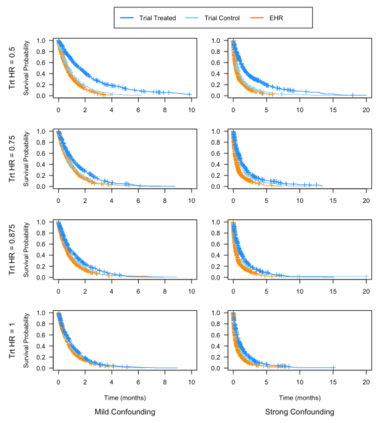
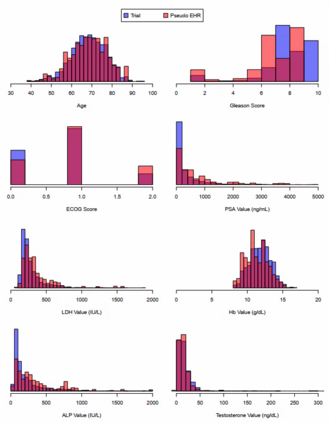
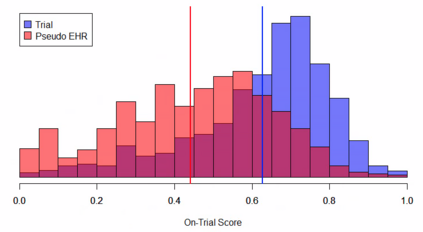
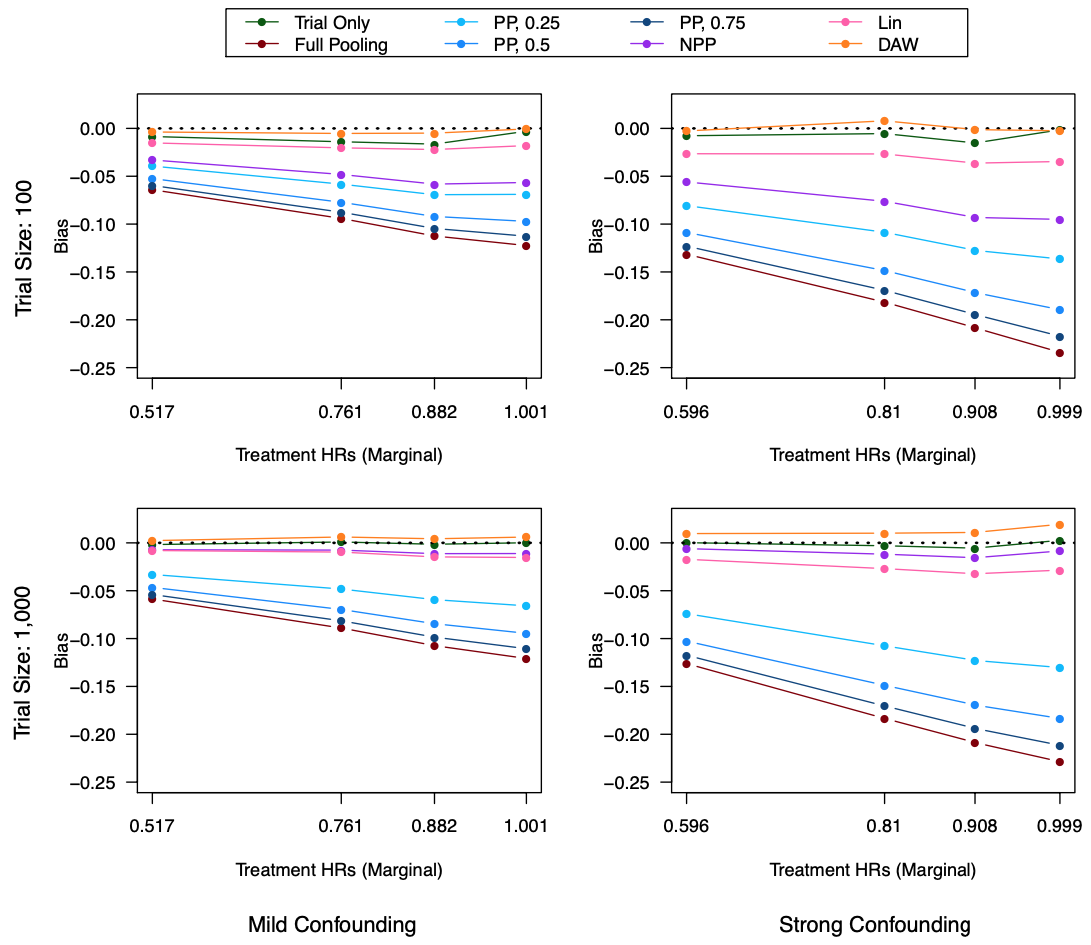
Clinical trials with a hybrid control arm (a control arm constructed from a combination of randomized patients and real-world data on patients receiving usual care in standard clinical practice) have the potential to decrease the cost of randomized trials while increasing the proportion of trial patients given access to novel therapeutics. However, due to stringent trial inclusion criteria and differences in care and data quality between trials and community practice, trial patients may have systematically different outcomes compared to their real-world counterparts. We propose a new method for analyses of trials with a hybrid control arm that efficiently controls bias and type I error. Under our proposed approach, selected real-world patients are weighted by a function of the "on-trial score," which reflects their similarity to trial patients. In contrast to previously developed hybrid control designs that assign the same weight to all real-world patients, our approach upweights of real-world patients who more closely resemble randomized control patients while dissimilar patients are discounted. Estimates of the treatment effect are obtained via Cox proportional hazards models. We compare our approach to existing approaches via simulations and apply these methods to a study using electronic health record data. Our proposed method is able to control type I error, minimize bias, and decrease variance when compared to using only trial data in nearly all scenarios examined. Therefore, our new approach can be used when conducting clinical trials by augmenting the standard-of-care arm with weighted patients from the EHR to increase power without inducing bias.
翻译:以混合控制器(由随机患者和在标准临床实践中接受正常护理的患者的真世界数据组合组成的控制器)进行临床试验,有可能降低随机试验的费用,同时增加接受新治疗的试验病人的比例;然而,由于严格的试验包容标准以及护理和数据质量在试验和社区实践之间差异很大,与实际世界的病人相比,试验病人可能具有系统性的不同结果;我们提议了一种新的方法,用混合控制器分析试验,有效控制偏向和第一类错误;根据我们提议的方法,选定的现实世界病人被“审判分”的功能加权,这反映了他们与试验病人的相似性;与以前开发的混合控制设计相比,对所有实际世界病人赋予同等份量,我们采用的方法使实际世界病人的随机控制病人比重增加,他们更接近于随机控制病人,同时对不同的病人进行折扣;我们建议的方法是通过模拟比较现有方法,并将这些方法应用于使用电子健康记录数据进行的研究;我们提出的方法是,在不使用电子健康记录数据的情况下,在不使用E类偏差的情况下,我们提议的选择方法能够控制E型试验时,因此只能使用新的偏差,在不使用新的选择中,因此只能使用新的偏差时使用新的选择方法来减少。