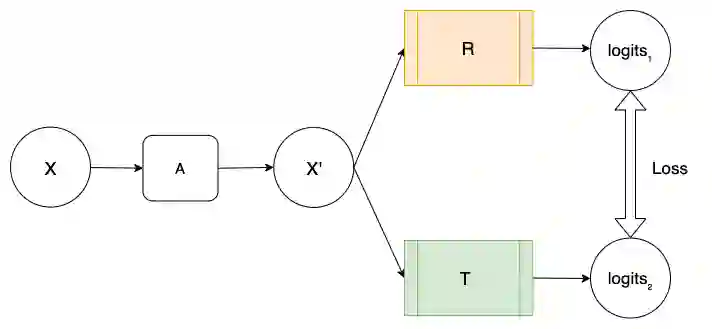
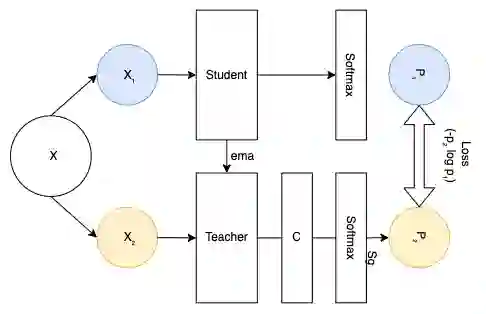
Recent advances in Deep Learning and Computer Vision have alleviated many of the bottlenecks, allowing algorithms to be label-free with better performance. Specifically, Transformers provide a global perspective of the image, which Convolutional Neural Networks (CNN) lack by design. Here we present Cross Architectural Self-Supervision, a novel self-supervised learning approach which leverages transformers and CNN simultaneously, while also being computationally accessible to general practitioners via easily available cloud services. Compared to existing state-of-the-art self-supervised learning approaches, we empirically show CASS trained CNNs, and Transformers gained an average of 8.5% with 100% labelled data, 7.3% with 10% labelled data, and 11.5% with 1% labelled data, across three diverse datasets. Notably, one of the employed datasets included histopathology slides of an autoimmune disease, a topic underrepresented in Medical Imaging and has minimal data. In addition, our findings reveal that CASS is twice as efficient as other state-of-the-art methods in terms of training time.
翻译:深层学习和计算机愿景的近期进展缓解了许多瓶颈,使得算法能够无标签地使用更好的性能。 具体地说,变异器提供了一种全局图像的全局视角,而进化神经网络(CNN)却因设计而缺乏这种视角。 我们在这里展示了Cross Artitual Information-Supervision(Cross Information-Sultive-Suspective),这是一种新的自我监督的学习方法,它同时利用变压器和CNN(CNN)来利用变压器和CNN(CNN),同时通过容易获得的云服务来计算一般从业者可以使用。与现有最先进的自我监督的学习方法相比,我们从经验上展示了CASS所训练的CNN,而变异器获得平均8.5%的标签数据为100%,7.3%的标签数据为10%,11.5%的标签数据为1%。 值得注意的是,其中一套使用的数据集包括自动免疫疾病病理学幻灯片,在医疗成像中比例过低,而且数据很少。 此外,我们的研究结果显示,在培训时间里,CASS比其他最先进的方法的效率要高一倍。