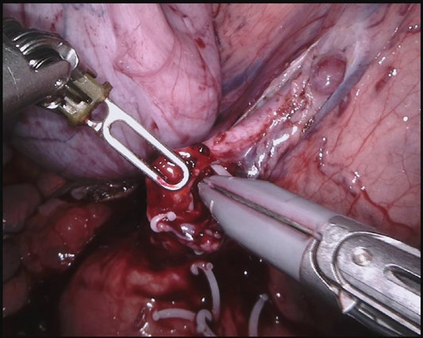
Data diversity and volume are crucial to the success of training deep learning models, while in the medical imaging field, the difficulty and cost of data collection and annotation are especially huge. Specifically in robotic surgery, data scarcity and imbalance have heavily affected the model accuracy and limited the design and deployment of deep learning-based surgical applications such as surgical instrument segmentation. Considering this, in this paper, we rethink the surgical instrument segmentation task and propose a one-to-many data generation solution that gets rid of the complicated and expensive process of data collection and annotation from robotic surgery. In our method, we only utilize a single surgical background tissue image and a few open-source instrument images as the seed images and apply multiple augmentations and blending techniques to synthesize amounts of image variations. In addition, we also introduce the chained augmentation mixing during training to further enhance the data diversities. The proposed approach is evaluated on the real datasets of the EndoVis-2018 and EndoVis-2017 surgical scene segmentation. Our empirical analysis suggests that without the high cost of data collection and annotation, we can achieve decent surgical instrument segmentation performance. Moreover, we also observe that our method can deal with novel instrument prediction in the deployment domain. We hope our inspiring results would encourage researchers to emphasize data-centric methods to overcome demanding deep learning limitations besides data shortage, such as class imbalance, domain adaptation, and incremental learning.
翻译:数据的多样性和数量对于培训深层次学习模式的成功至关重要,而在医学成像领域,数据收集和批注的难度和成本特别巨大。具体在机器人外科手术中,数据稀缺和不平衡严重影响了模型的准确性,限制了深层次的学习外科手术应用的设计和部署,例如外科仪器分解。考虑到这一点,我们在本文件中重新思考外科仪器分解任务,并提出一个一对多数据生成解决方案,摆脱了复杂和昂贵的机器人外科手术数据收集和批注过程。在我们的方法中,我们只能使用单一手术背景组织图象和少数开源仪器图象作为种子图象,并应用多重增强和混合技术来综合图像变异的数量。此外,我们还在培训中引入了连锁的增强组合,以进一步加强数据多样性。我们建议的方法是在EndoVis 2018 和 EndoVis 2017 外科场景分解的真正数据集上进行评估。我们的经验分析表明,如果没有高成本数据收集和批注,我们只能实现体面的外科仪器分解仪图象学分解功能。此外,我们还观察了多种扩增压性分析方法,因此,我们又将鼓励高层次数据再学习。我们的研究分析方法。我们的研究再学习。