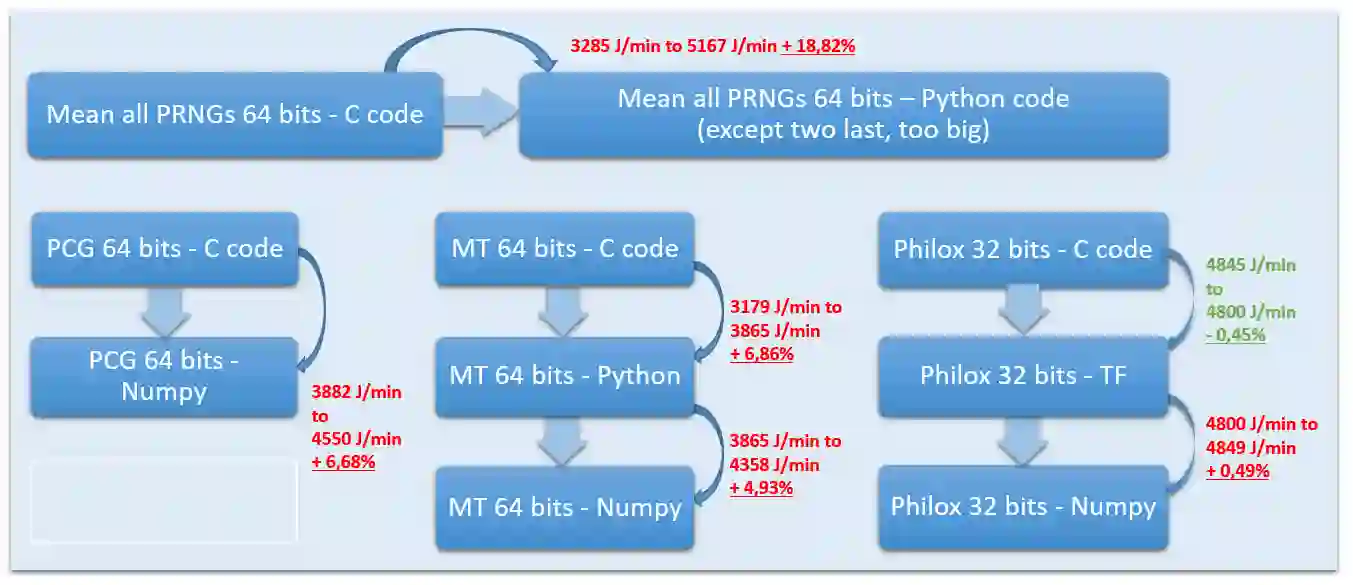
Pseudo-Random Number Generators (PRNGs) have become ubiquitous in machine learning technologies because they are interesting for numerous methods. The field of machine learning holds the potential for substantial advancements across various domains, as exemplified by recent breakthroughs in Large Language Models (LLMs). However, despite the growing interest, persistent concerns include issues related to reproducibility and energy consumption. Reproducibility is crucial for robust scientific inquiry and explainability, while energy efficiency underscores the imperative to conserve finite global resources. This study delves into the investigation of whether the leading Pseudo-Random Number Generators (PRNGs) employed in machine learning languages, libraries, and frameworks uphold statistical quality and numerical reproducibility when compared to the original C implementation of the respective PRNG algorithms. Additionally, we aim to evaluate the time efficiency and energy consumption of various implementations. Our experiments encompass Python, NumPy, TensorFlow, and PyTorch, utilizing the Mersenne Twister, PCG, and Philox algorithms. Remarkably, we verified that the temporal performance of machine learning technologies closely aligns with that of C-based implementations, with instances of achieving even superior performances. On the other hand, it is noteworthy that ML technologies consumed only 10% more energy than their C-implementation counterparts. However, while statistical quality was found to be comparable, achieving numerical reproducibility across different platforms for identical seeds and algorithms was not achieved.
翻译:暂无翻译