论文浅尝 | 利用 RNN 和 CNN 构建基于 FreeBase 的问答系统

Qu Y,Liu J, Kang L, et al. Question Answering over Freebase via Attentive RNN withSimilarity Matrix based CNN[J]. arXiv preprint arXiv:1804.03317, 2018.
概述
随着近年来知识库的快速发展,基于知识库的问答系统(KBQA )吸引了业界的广泛关注。该类问答系统秉承先编码再比较的设计思路,即先将问题和知识库中的三元组联合编码至统一的向量空间,然后在该向量空间内做问题和候选答案间的相似度计算。该类方法简单有效,可操作性比较强,然而忽视了很多自然语言词面的原始信息。因此,本文中提出了一种 Attentive RNN with Similarity Matrix based CNN(AR-SMCNN)模型,利用 RNN 和 CNN 自身的结构特点分层提取有用信息。文中使用 RNN 的序列建模本质来捕获语义级关联,并使用注意机制同时跟踪实体和关系。同时,文中使用基于 CNN 的相似矩阵和双向池化操作建模数据间空间相关性的强度来计算词语字面的匹配程度。此外,文中设计了一种新的实体检测启发式扩展方法,大大降低了噪声的影响。文中的方法在准确性和效率上都超越了SimpleQuestion基准测试的当前最好水平。
模型
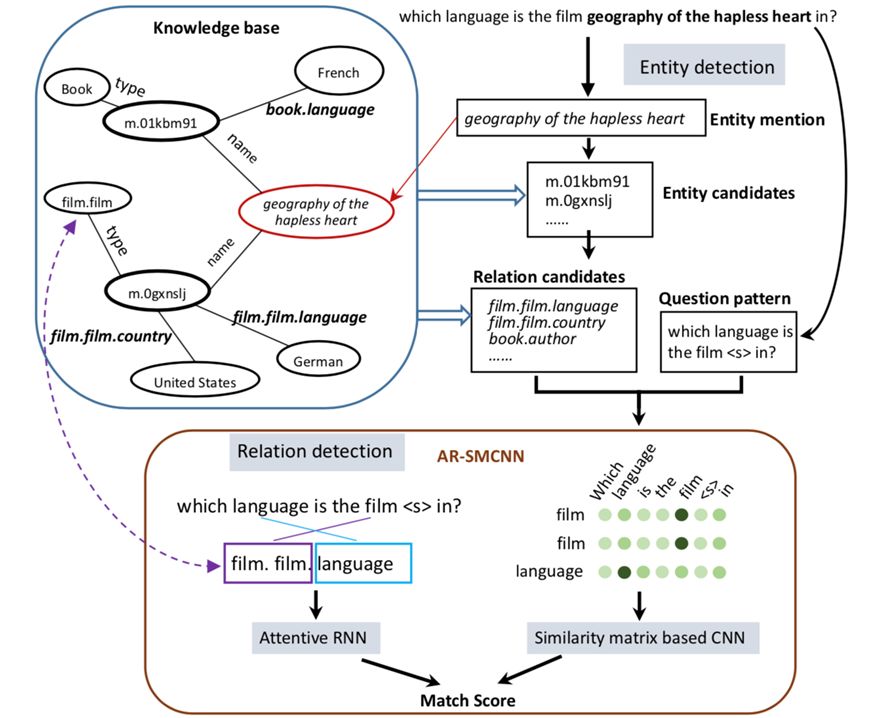
模型如上图所示,假设单关系问题可以通过用单一主题和关系论证来查询知识库来回答。因此,只需要元组(s,r)来匹配问题。只要s和r的预测都是正确的,就可以直接得到答案(这显然对应于o)。根据上述假设,问题可以通过以下两个步骤来解决:
确定问题涉及的Freebase中的候选实体。给定一个问题 Q,我们需要找出实体提及(mention)X,那么名称或别名与实体提及相同的所有实体将组成实体候选E.现在E中的所有实体都具有相同的实体名称,因此我们暂时无法区分他们。具体地,模型中将命名实体识别转换成了基于 Bi-LSTM 完成的序列标注任务。
所有与 E 中的实体相关的关系都被视为候选关系,命名为 R. 我们将问题转换为模式 P,它是通过用<e>替换问题中的提及而创建的。为了找出与问题真正相关的关系,我们将 P 与 R 中的每个关系进行比较并对它们进行评分,然后将得分最高的关系作为最终结果。为了更高的进行关系匹配,模型从单词字面表达和语义两个层面对自然语言进行了建模。具体操作如下图所示:
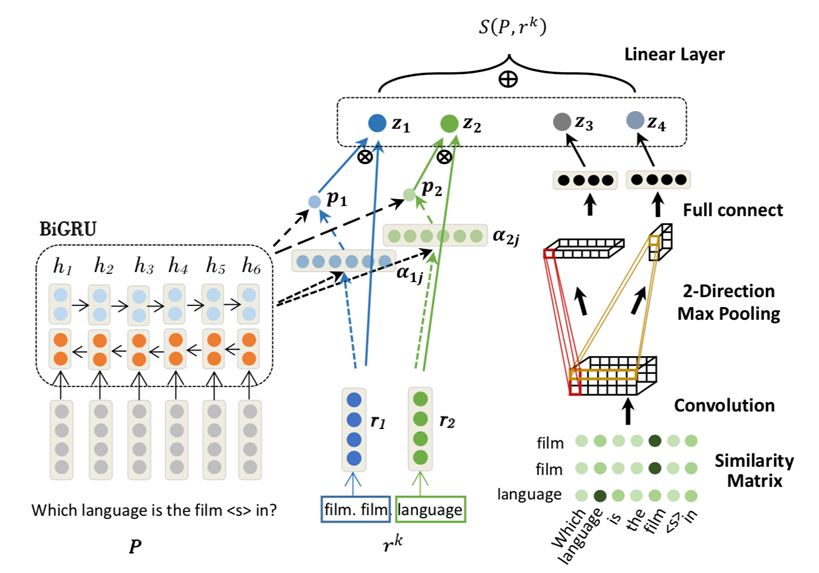
图中所示的 AR-SMCNN 模型,输入是经替换 mention 后的问题模版(pattern)P 和候选关系 rk。模型左边的部分是结合了 attention 机制的 BiGRU,用于从语义层面进行建模。右边的部分是CNN上的相似性矩阵,用于从字面角度进行建模。最终将特征 𝑧1,𝑧2,𝑧3,𝑧4连接在一起并通过线性层得到最终的候选关系分数 𝑆(𝑃,𝑟𝑘)。
实验结果
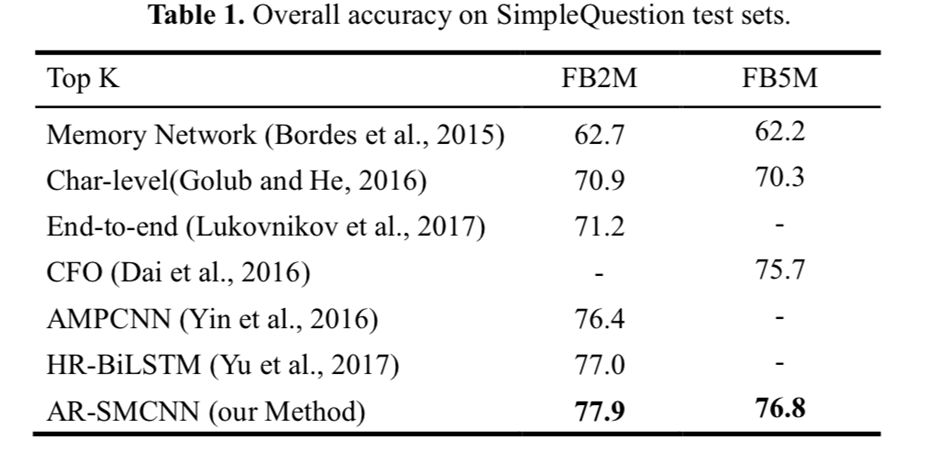
如表 1 所示,文中提出的方法在 FB2M 和 FB5M 设置上达到了 77.9% 和76.8% 的精确度,分别超过了之前的最佳结果 0.9% 和 1.1%。
总结
在这篇文章中,作者提出了一种基于神经网络的新颖方法来回答大规模知识库中的单关系问题,它利用 RNN 和 CNN 的优势互补来捕获语义和文字相关信息。通过省略实体匹配模型使得模型简单化,所提出的方法实现了有竞争力的结果。尽管所提出的方法仅限于单关系问题,但这项工作可以作为未来开发更先进的基于神经网络的 QA 方法的基础,可以处理更复杂的问题。
论文笔记整理:吴桐桐,东南大学博士生,研究方向为自然语言问答。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。





