论文浅尝 | 知识图谱问答中的层次类型约束主题实体识别

Citation:Qiu, Y., Li, M., Wang, Y., Jia, Y., & Jin, X.(2018). Hierarchical Type Constrained Topic Entity Detection for Knowledge Base Question Answering. Companion of the Web Conference (pp.35-36).
动机
对于 KBQA 任务,有两个最为重要的部分:其一是问题实体识别,即将问题中的主题实体识别出来,并与 KB 做实体链接;其二是谓词映射。对于主题实体识别任务,之前的做法多为依靠字符串相似度,再辅以人工抽取的特征和规则来完成的。但是这样的做法并没有将问题的语义与实体类型、实体关系这样的实体信息考虑进来。实体类型和实体关系,很大程度上,是与问题的上下文语义相关的。当只考虑实体关系时,会遇到 zero-shot 的问题,即测试集中某实体的关系,是在训练集中没有遇到过的,这样的实体关系就没法准确地用向量表达。
因此,为了解决上述问题,本文首先利用 entity type(实体类型)的层次结构(主要为实体类型之间的父子关系),来解决 zero-shot 的问题。如同利用 wordnet 计算 word 相似度的做法一般,文章将父类型的“语义”视为所有子类型的“语义”之和。一个实体总是能够与粗颗粒的父类型相关,例如一个实体至少能够与最粗颗粒的 person、location 等类型相连。这样,利用实体所述的类型,在考虑实体上下文时,就可以一定程度上弥补实体关系的zero-shot问题。此外,本文建立了一个神经网络模型 Hierarchical Type constrained Topic Entity Detection (HTTED),利用问题上下文、实体类型、实体关系的语义,来计算候选实体与问题上下文的相似度,选取最相似的实体,来解决 NER 问题。经过实验证明,HTTED 系统对比传统的系统来说,达到了目前最优的实体识别效果。
贡献
文章的贡献有:
(1)利用父子类型的层次结构来解决稀疏类型训练不充分的问题;
(2)设计了基于 LSTM 的 HTTED 模型,进行主题实体识别任务;
(3)提出的模型通过实验验证取得了 state-of-art 的效果。
方法
⒈本文首先对于父子类型的层次结构进行解释和论述,也是HTTED的核心思想。
本文认为,父类型的语义视为接近于所有子类型的语义之和。例如父类型 organization 的语义,就相当于子类型 company、enterprise 等语义之和。如果类型是由定维向量表示,那么父类型的向量就是子类型的向量之和。此外,由于在数据集中,属于子类型的实体比较稀疏,而父类型的实体稠密,如果不采用文中的方法,那么稀疏的子类型将会得不到充分的训练。若将父类型以子类型表示,那么父子类型都可以得到充分地训练。
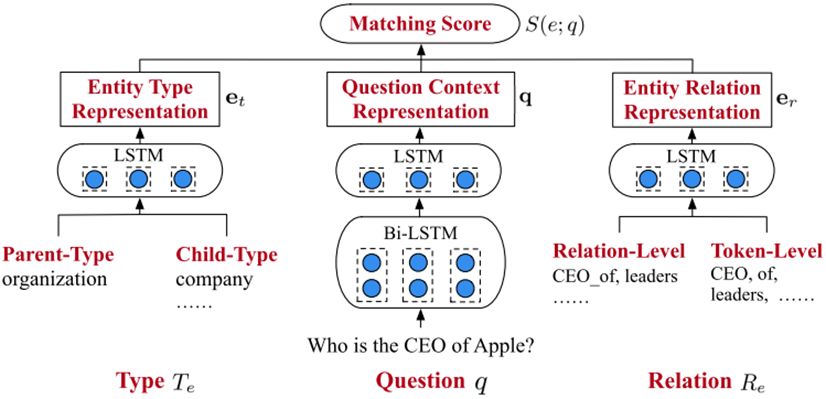
图1 HTTED模型图
⒉其次是对文中模型的解释。如上图1所示,HTTED 使用了三个编码器来对不同成分编码。
其一,是问答上下文编码器,即将问题经过分词后得到的 tokens,以预训练得到的词向量来表示,并依次输入双向 LSTM 进行第一层的编码;此后,将双向 LSTM 得到的输出拼接,再输入第二层的 LSTM 进行编码,即得到表示问题上下文的 d 维向量 q。
其二,是实体类型编码器,即对于某个候选实体e,得到其连接的类型,并将父类型以所有子类型向量之和表示,再将这些类型对应的向量输入一个 LSTM 中进行编码,得到实体类型的 d 维向量 et。
其三,是实体关系编码器,即对于某个候选实体 e,得到其所有实体关系,并表示成向量。此外,对于实体关系,将其关系名切割为 tokens,并以词向量表示。然后将实体关系和实体关系名这两种向量,输入一个 LSTM 中进行编码,得到实体关系的d维向量 er。
得到三个向量后,文章认为实体的语义可以由实体类型、实体关系近似表达,所以有
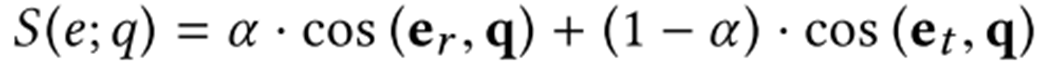
而在训练时,设置一个 margin,则 ranking loss 为:
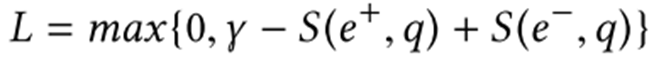
其中γ为超参数。
实验
文章使用单关系问答数据集 SimpleQuestions 和知识图谱 FB2M,并有 112 个具有层次父子关系的实体类型。HTTED 的词向量为经过预训练的,关系向量是初始随机的,而类型向量中,叶子类型初始随机,父类型的向量由子类型的向量累加得到。如下图2所示,为 HTTED 与其他系统的效果对比,其中 -Hierarchy表示 HTTED 去除了实体类型的层次结构表示。
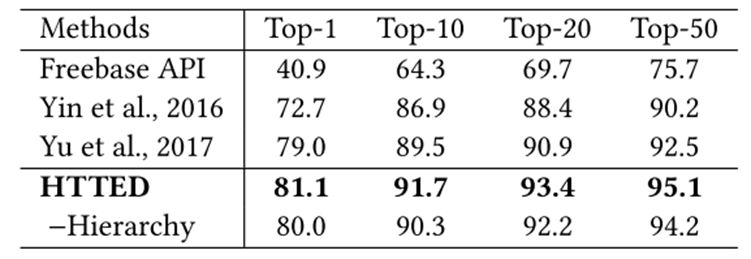
图2 主题实体识别效果对比图
由图2可见,HTTED 为 state-of-art 的效果。并且,将实体类型的层次结构去除,HTTED 的准确性下降很多。可见层次类型约束对于该模型的重要性。
由下图3可见,由于使用了层次结构的类型,同名的实体被识别出来,但是与问题上下文更相关的实体都被挑选出来,所以能够正确识别到主题实体。
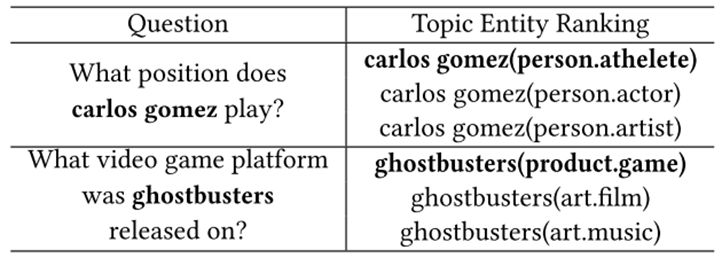
图3 主题实体识别示例图
总结
这篇文章,主要有两个主要工作:其一,是引入了层次结构的实体类型约束,来表达实体的语义,使得与问题上下文相关的实体,更容易被找到;其二,是建立了基于 LSTM 的 HTTED 模型,提高了主题实体识别的效果。
论文笔记整理:花云程,东南大学博士,研究方向为自然语言处理、知识图谱问答。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。


