【ICLR2021】基于返回的对比表征学习在强化学习中的应用

Return-Based Contrastive Representation Learning for Reinforcement Learning
Authors: Guoqing Liu, Chuheng Zhang, Li Zhao, Tao Qin, Jinhua Zhu, Jian Li, Nenghai Yu, Tie-Yan Liu
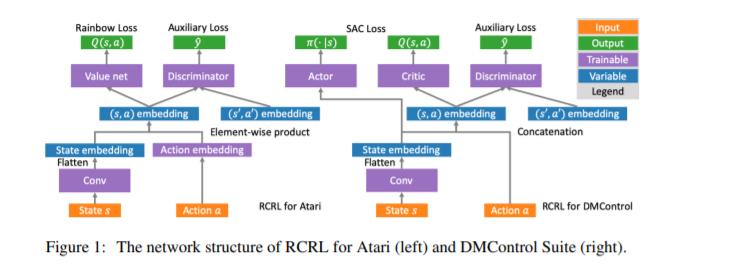
近年来,在深度强化学习(deep reinforcement learning, RL)中,各种辅助任务被提出来加速表示学习和提高样本效率。然而,现有的辅助任务没有考虑到RL问题的特点,是无监督的。通过利用回报这一RL中最重要的反馈信号,我们提出了一种新的辅助任务,迫使学习到的表示区分具有不同回报的状态-行为对。我们的辅助损失在理论上是合理的,以学习捕获一种新的形式的状态-行为抽象的结构的表征,在这种结构下,具有相似回报分布的状态-行为对被聚集在一起。在低数据的情况下,我们的算法在Atari游戏和DeepMind控制套件的复杂任务上优于强大的基线,在与现有的辅助任务相结合的情况下获得了更好的性能。
https://www.zhuanzhi.ai/paper/7c66011b0d7a2fa1fc3825853caf383e
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“RCRL” 可以获取《【ICLR2021】基于返回的对比表征学习在强化学习中的应用》专知下载链接索引



登录查看更多
相关内容
专知会员服务
17+阅读 · 2020年7月14日
Arxiv
10+阅读 · 2021年2月22日




相关VIP内容
专知会员服务
17+阅读 · 2020年7月14日
相关资讯
相关论文
Arxiv
10+阅读 · 2021年2月22日