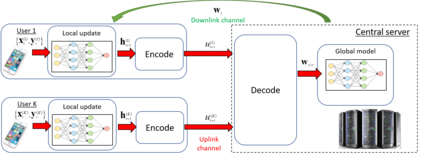
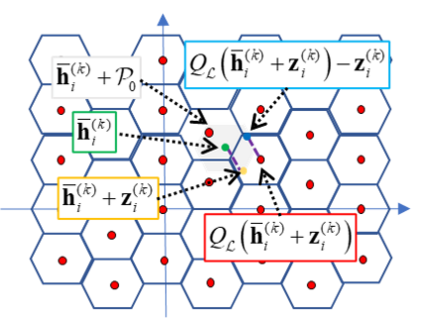
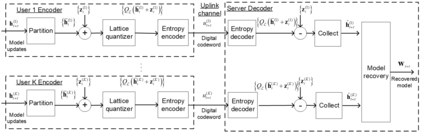
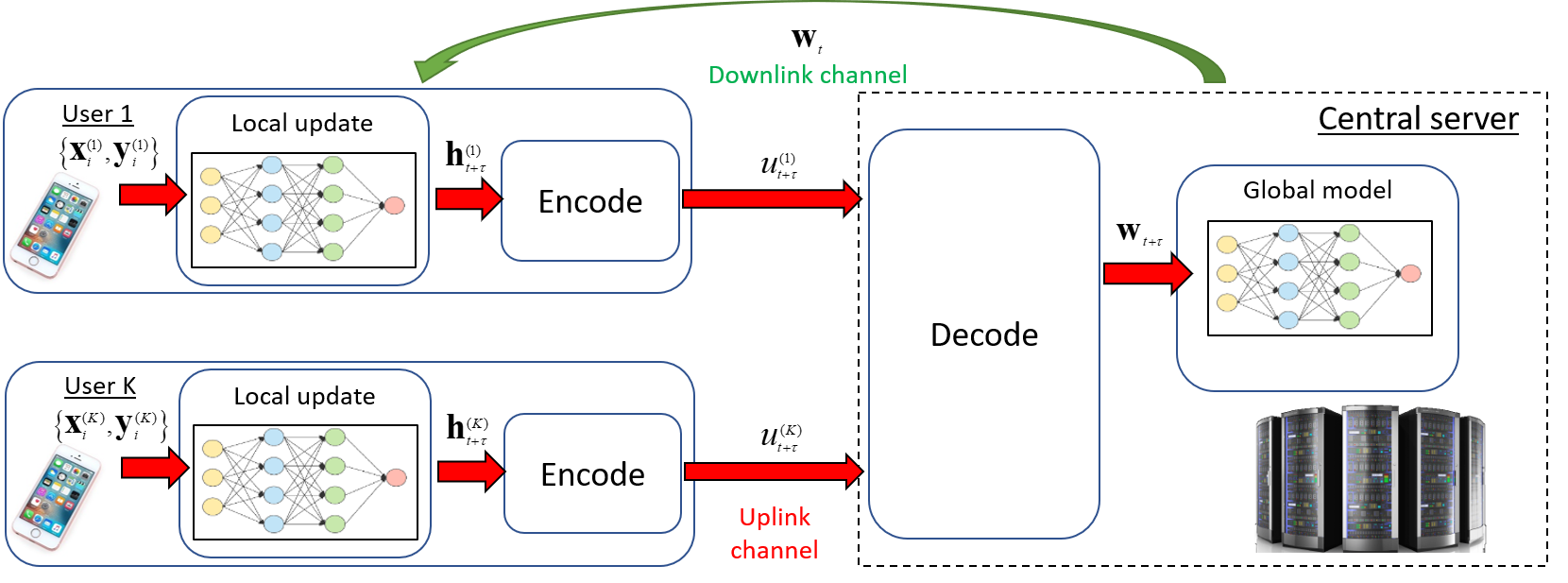
Traditional deep learning models are trained at a centralized server using labeled data samples collected from end devices or users. Such data samples often include private information, which the users may not be willing to share. Federated learning (FL) is an emerging approach to train such learning models without requiring the users to share their possibly private labeled data. In FL, each user trains its copy of the learning model locally. The server then collects the individual updates and aggregates them into a global model. A major challenge that arises in this method is the need of each user to efficiently transmit its learned model over the throughput limited uplink channel. In this work, we tackle this challenge using tools from quantization theory. In particular, we identify the unique characteristics associated with conveying trained models over rate-constrained channels, and propose a suitable quantization scheme for such settings, referred to as universal vector quantization for FL (UVeQFed). We show that combining universal vector quantization methods with FL yields a decentralized training system in which the compression of the trained models induces only a minimum distortion. We then theoretically analyze the distortion, showing that it vanishes as the number of users grows. We also characterize the convergence of models trained with the traditional federated averaging method combined with UVeQFed to the model which minimizes the loss function. Our numerical results demonstrate the gains of UVeQFed over previously proposed methods in terms of both distortion induced in quantization and accuracy of the resulting aggregated model.
翻译:在中央服务器上,使用从终端设备或用户收集的标签数据样本,对传统深层学习模式进行培训。这些数据样本通常包括私人信息,用户可能不愿意分享这些信息。联邦学习(FL)是一种新兴方法,用于培训这类学习模式,而不需要用户分享其可能的私人标签数据。在FL,每个用户都在当地培训学习模式的副本。服务器然后收集个人更新,将其汇总成一个全球模式。这一方法中出现的一个主要挑战是每个用户需要通过通过通过通过截肢有限的上链接通道有效传输其所学的模型。在这项工作中,我们利用量化理论的工具来应对这一挑战。特别是,我们确定与传递经过培训的模型相比,在超速限制的频道上传递经过培训的模型有关的独特特点,并为这些环境提出适当的量化方案,称为FL(UVeQF)的通用矢量定量化模型。我们显示,将通用矢量定量模型与ULL的配置模型结合起来,只有最低限度的扭曲。我们然后从理论上分析扭曲情况,表明它会与经过培训的用户的惯性损失方法相比,会逐渐减少成本。