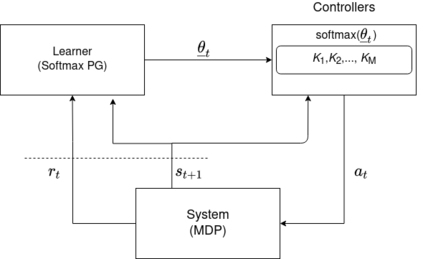
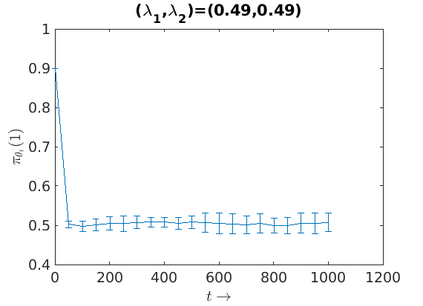
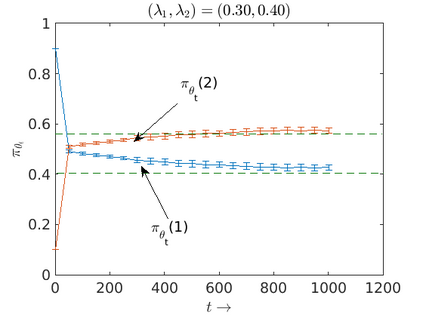
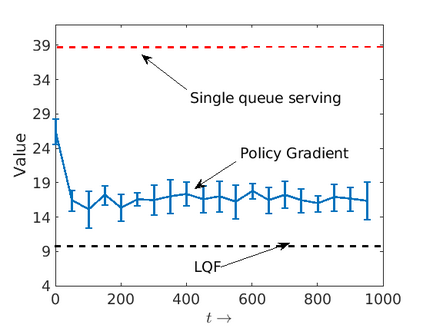
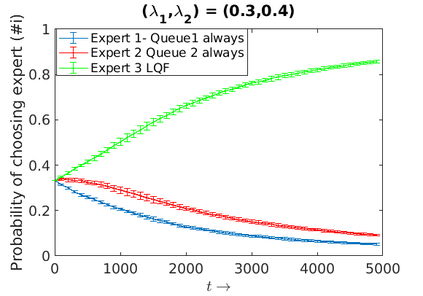
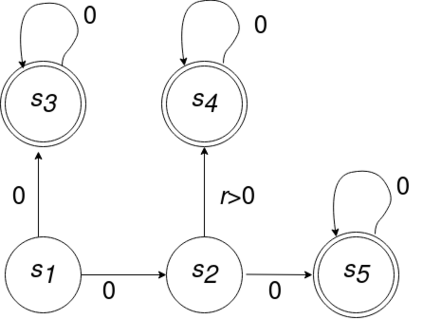
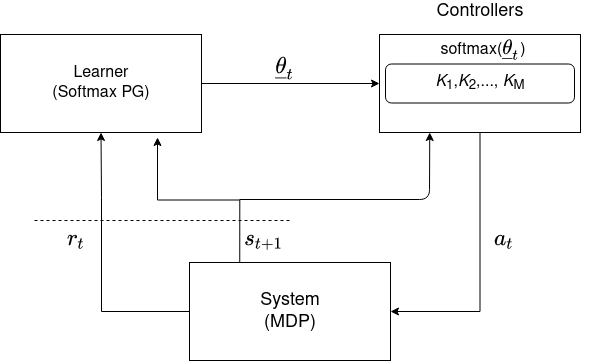
We consider an improper reinforcement learning setting where the learner is given M base controllers for an unknown Markov Decision Process, and wishes to combine them optimally to produce a potentially new controller that can outperform each of the base ones. We propose a gradient-based approach that operates over a class of improper mixtures of the controllers. The value function of the mixture and its gradient may not be available in closed-form; however, we show that we can employ rollouts and simultaneous perturbation stochastic approximation (SPSA) for explicit gradient descent optimization. We derive convergence and convergence rate guarantees for the approach assuming access to a gradient oracle. Numerical results on a challenging constrained queueing task show that our improper policy optimization algorithm can stabilize the system even when each constituent policy at its disposal is unstable.
翻译:我们考虑一种不适当的强化学习环境,让学习者获得M基控制器,用于一个未知的马尔科夫决定程序,我们希望将它们最佳地结合起来,以产生一个可能的新控制器,其性能优于每个基数。我们建议一种基于梯度的方法,在控制器的某一类不适当的混合物上运行。混合物及其梯度的价值功能可能无法以闭式形式提供;然而,我们表明,我们可以使用推出和同时的扰动近似近似(SPSA)来进行明确的梯度下降优化。我们为假设使用梯度或电弧的方法获得趋同率和趋同率保证。 具有挑战性的排队限制任务的数字结果显示,我们不当的政策优化算法可以稳定系统,即使其使用的每个组成政策都不稳定。