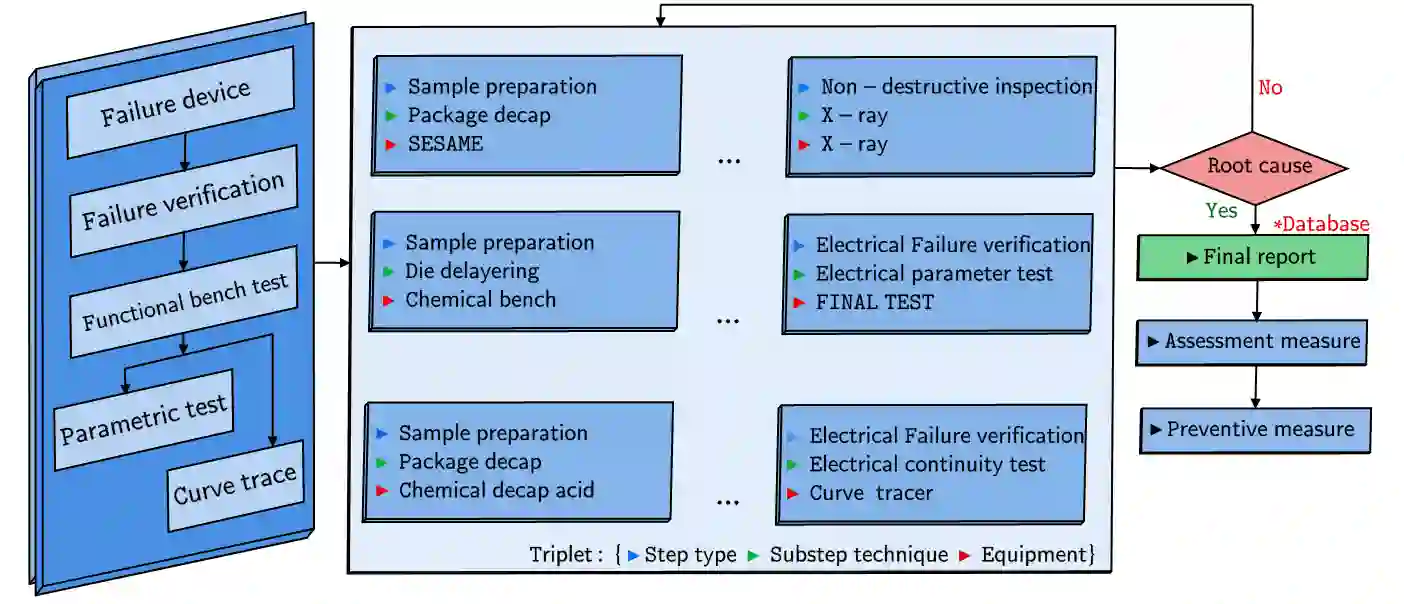
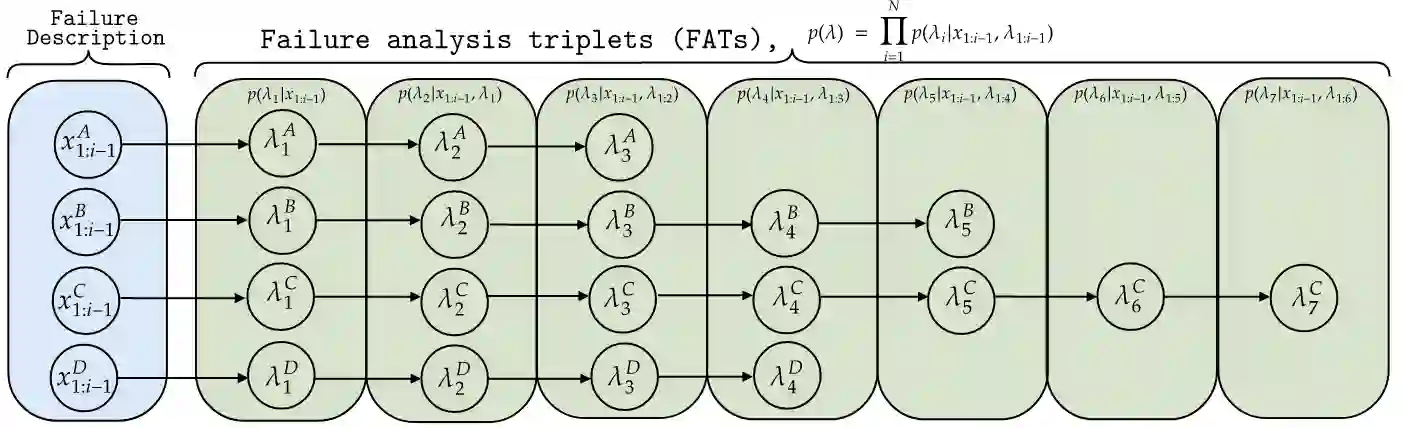
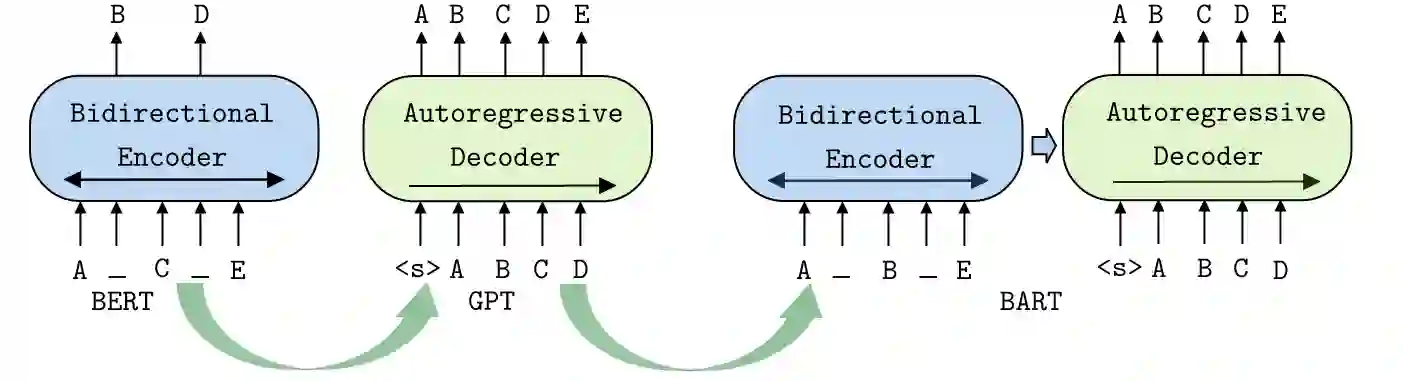
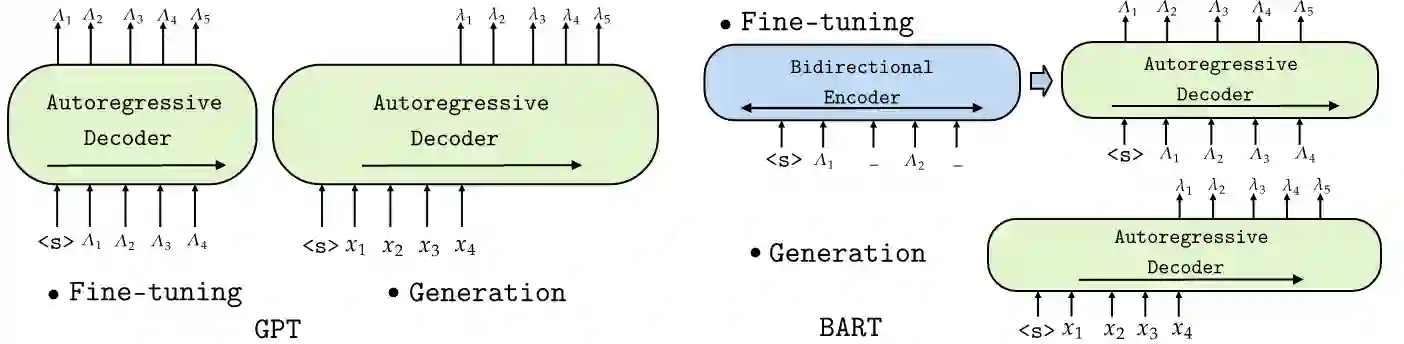
Pre-trained Language Models recently gained traction in the Natural Language Processing (NLP) domain for text summarization, generation and question-answering tasks. This stems from the innovation introduced in Transformer models and their overwhelming performance compared with Recurrent Neural Network Models (Long Short Term Memory (LSTM)). In this paper, we leverage the attention mechanism of pre-trained causal language models such as Transformer model for the downstream task of generating Failure Analysis Triplets (FATs) - a sequence of steps for analyzing defected components in the semiconductor industry. We compare different transformer models for this generative task and observe that Generative Pre-trained Transformer 2 (GPT2) outperformed other transformer model for the failure analysis triplet generation (FATG) task. In particular, we observe that GPT2 (trained on 1.5B parameters) outperforms pre-trained BERT, BART and GPT3 by a large margin on ROUGE. Furthermore, we introduce Levenshstein Sequential Evaluation metric (LESE) for better evaluation of the structured FAT data and show that it compares exactly with human judgment than existing metrics.
翻译:经过培训的语文模型最近在自然语言处理(NLP)域中获得了文字归纳、生成和问答任务方面的牵引力,这源于在变异模型中采用的创新及其与经常性神经网络模型(长期短期内存)相比的压倒性性性能。在本文件中,我们利用预先培训的因果语言模型的注意机制,如生成失败分析三联(FATs)的下游任务变异模型(FATs)——这是分析半导体工业中缺陷组成部分的一系列步骤。我们比较了这一基因化任务的不同变异模型,并观察到,预受培训的变异2(GPT2)优于其他变异模型,以进行故障分析三联(FATG)任务。特别是,我们观察到,GPT2(经过1.5B参数培训)在RET、BART和GPT3上比ROGE大幅度地形成预先培训的BERT、BART和GPT3。此外,我们引入了LESEEEE评价标准,以更好地评价结构化FAT数据,并显示它与人类判断的精确比现有指标。