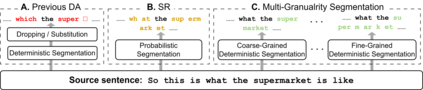
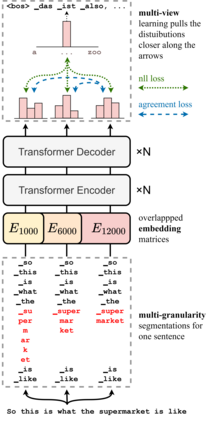
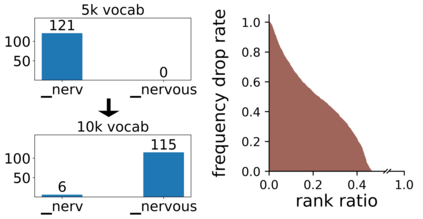
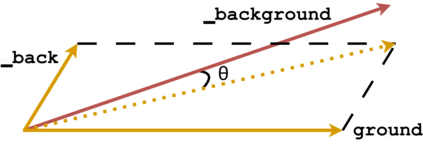
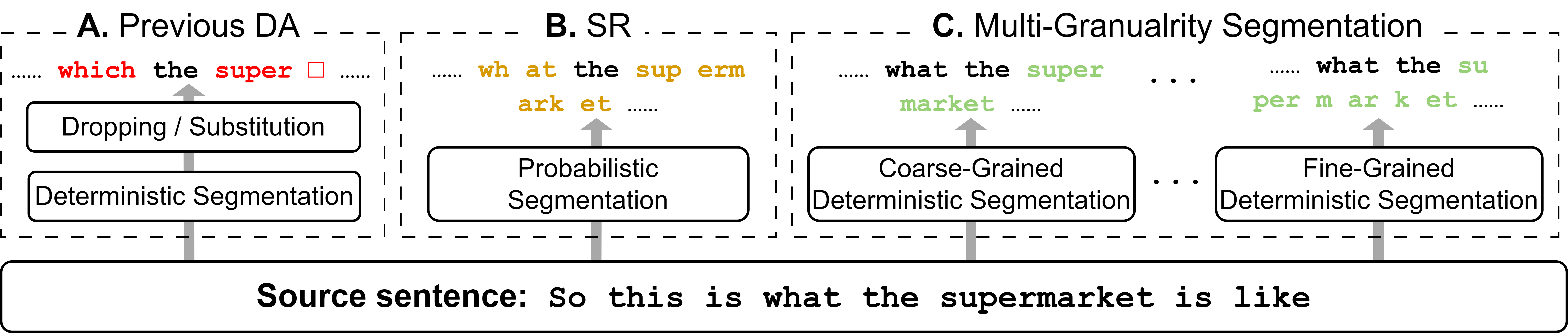
Data augmentation is an effective way to diversify corpora in machine translation, but previous methods may introduce semantic inconsistency between original and augmented data because of irreversible operations and random subword sampling procedures. To generate both symbolically diverse and semantically consistent augmentation data, we propose Deterministic Reversible Data Augmentation (DRDA), a simple but effective data augmentation method for neural machine translation. DRDA adopts deterministic segmentations and reversible operations to generate multi-granularity subword representations and pulls them closer together with multi-view techniques. With no extra corpora or model changes required, DRDA outperforms strong baselines on several translation tasks with a clear margin (up to 4.3 BLEU gain over Transformer) and exhibits good robustness in noisy, low-resource, and cross-domain datasets.
翻译:暂无翻译