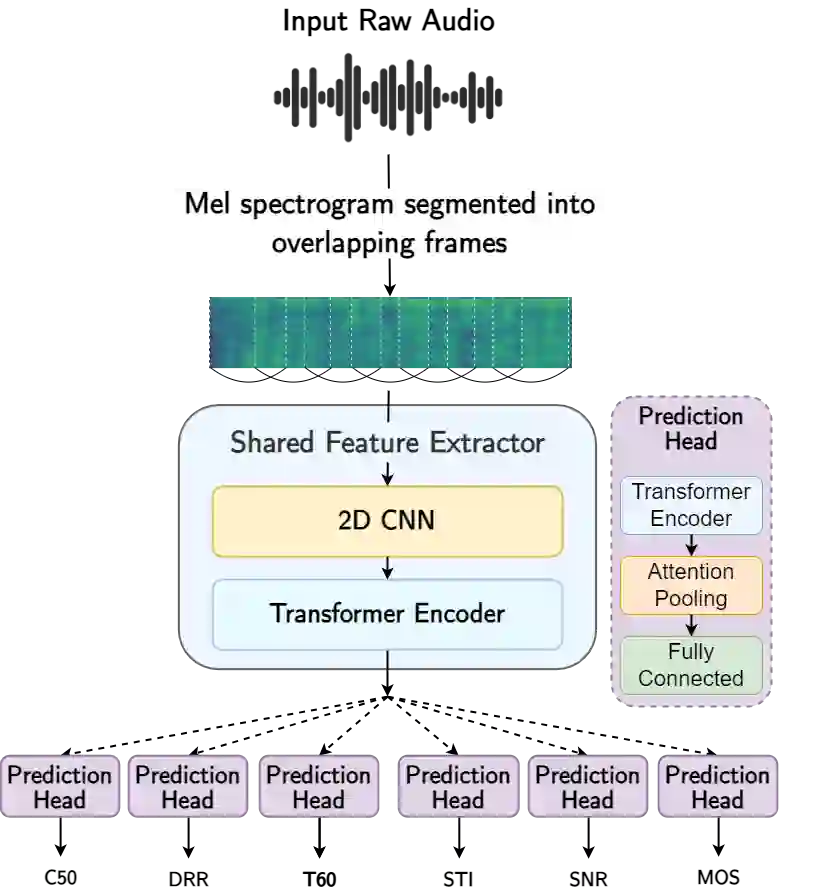
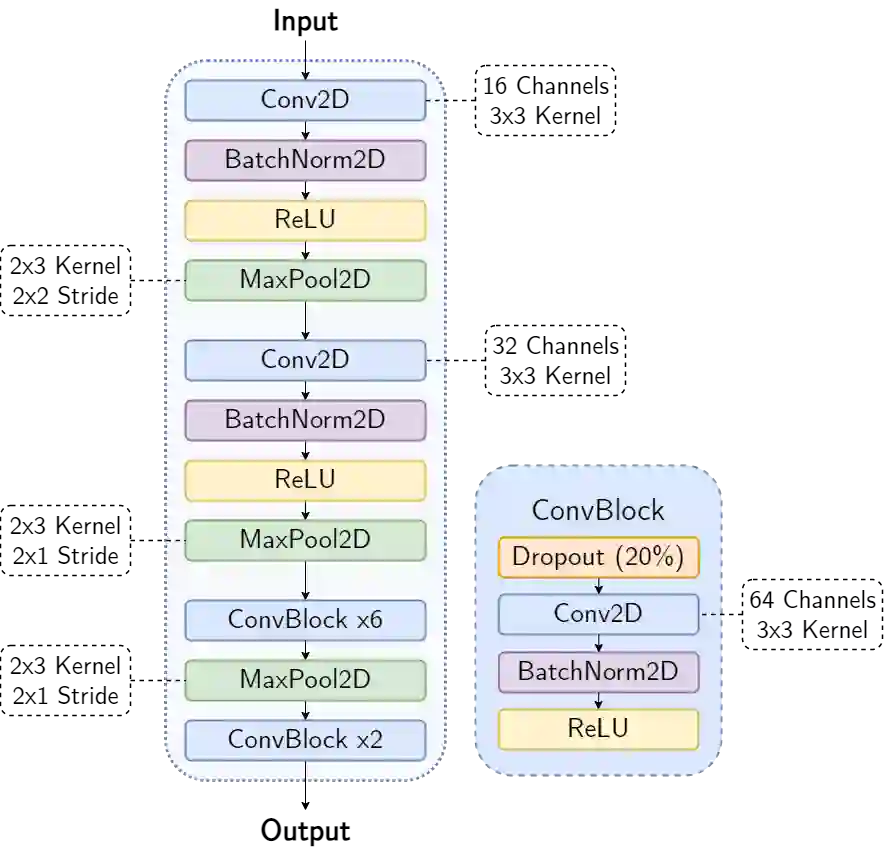
The acoustic environment can degrade speech quality during communication (e.g., video call, remote presentation, outside voice recording), and its impact is often unknown. Objective metrics for speech quality have proven challenging to develop given the multi-dimensionality of factors that affect speech quality and the difficulty of collecting labeled data. Hypothesizing the impact of acoustics on speech quality, this paper presents MOSRA: a non-intrusive multi-dimensional speech quality metric that can predict room acoustics parameters (SNR, STI, T60, DRR, and C50) alongside the overall mean opinion score (MOS) for speech quality. By explicitly optimizing the model to learn these room acoustics parameters, we can extract more informative features and improve the generalization for the MOS task when the training data is limited. Furthermore, we also show that this joint training method enhances the blind estimation of room acoustics, improving the performance of current state-of-the-art models. An additional side-effect of this joint prediction is the improvement in the explainability of the predictions, which is a valuable feature for many applications.
翻译:鉴于影响语言质量的因素的多维性以及难以收集贴标签的数据,声音环境在交流期间可能会降低语言质量(例如视频电话、远程演示、外部语音记录),其影响往往不为人知。鉴于影响语言质量的因素的多维性以及难以收集标签数据,语言质量的客观指标证明具有挑战性。 假设声学对语言质量的影响,本文介绍了MOSRA:一种非侵入性的多维语言质量指标,可以预测室内声学参数(SNR、STI、T60、DRR和C50),同时预测语音质量的总体平均评分(MOS)。通过明确优化模型学习这些室声学参数,我们可以提取更多的信息特征,并在培训数据有限时改进MOS任务的一般化。此外,我们还表明,这种联合培训方法可以提高对室声学的盲度估计,提高当前最新模型的性能。这种联合预测的另一个副作用是改进预测的可解释性,这是许多应用的宝贵特征。