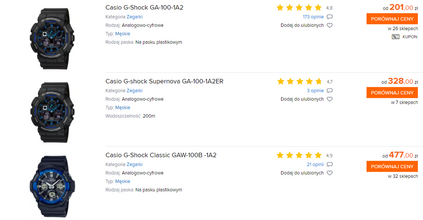
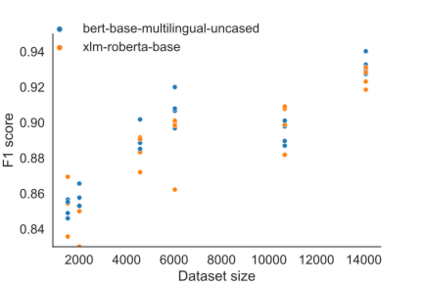
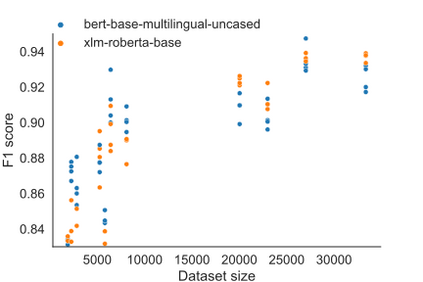
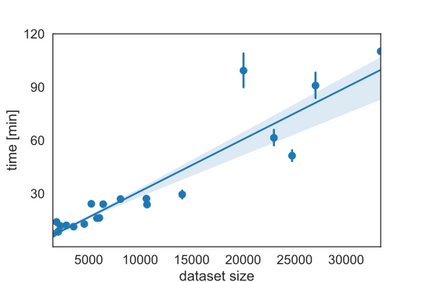
Product matching corresponds to the task of matching identical products across different data sources. It typically employs available product features which, apart from being multimodal, i.e., comprised of various data types, might be non-homogeneous and incomplete. The paper shows that pre-trained, multilingual Transformer models, after fine-tuning, are suitable for solving the product matching problem using textual features both in English and Polish languages. We tested multilingual mBERT and XLM-RoBERTa models in English on Web Data Commons - training dataset and gold standard for large-scale product matching. The obtained results show that these models perform similarly to the latest solutions tested on this set, and in some cases, the results were even better. Additionally, we prepared a new dataset entirely in Polish and based on offers in selected categories obtained from several online stores for the research purpose. It is the first open dataset for product matching tasks in Polish, which allows comparing the effectiveness of the pre-trained models. Thus, we also showed the baseline results obtained by the fine-tuned mBERT and XLM-RoBERTa models on the Polish datasets.
翻译:产品匹配与将不同数据来源的相同产品进行匹配的任务相对应。产品匹配通常使用现有产品特征,这些特征除了包括多种数据类型之外,也可能是非同质和不完整的。文件表明,经过微调的经过事先训练的多语言变异器模型,适合使用英文和波兰文的文本特征解决产品匹配问题。我们在网络数据公用中测试了英文多语言的 mBERT 和 XLM-ROBERTA 模型,用于大规模产品匹配的培训数据集和黄金标准。获得的结果显示,这些模型与在这个集上测试的最新解决方案类似,在某些情况下,其结果甚至更好。此外,我们完全用波兰语编制了一套新的数据集,并以若干在线商店为研究目的提供的选定类别的报价为基础。这是波兰境内产品匹配任务的第一个开放数据集,可以比较预先培训的模型的有效性。因此,我们还展示了波兰数据集中微调的 mBERT 和 XLM-ROBERTA模型所取得的基线结果。