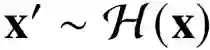Deep learning-based image retrieval has been emphasized in computer vision. Representation embedding extracted by deep neural networks (DNNs) not only aims at containing semantic information of the image, but also can manage large-scale image retrieval tasks. In this work, we propose a deep learning-based image retrieval approach using homography transformation augmented contrastive learning to perform large-scale synthetic aperture radar (SAR) image search tasks. Moreover, we propose a training method for the DNNs induced by contrastive learning that does not require any labeling procedure. This may enable tractability of large-scale datasets with relative ease. Finally, we verify the performance of the proposed method by conducting experiments on the polarimetric SAR image datasets.
翻译:在计算机视野中强调深层的基于学习的图像检索。深层神经网络(DNNs)所提取的图像嵌入演示不仅旨在包含图像的语义信息,而且能够管理大规模图像检索任务。在这项工作中,我们提议采用深层基于学习的图像检索方法,使用同族体变换来增强对比学习,以完成大型合成孔径雷达(SAR)图像搜索任务。此外,我们提议了一种通过对比学习为DNes提供的培训方法,不需要任何标签程序。这可能会使大型数据集能够相对容易地移动。最后,我们通过对极度合成孔径雷达图像数据集进行实验来验证拟议方法的性能。