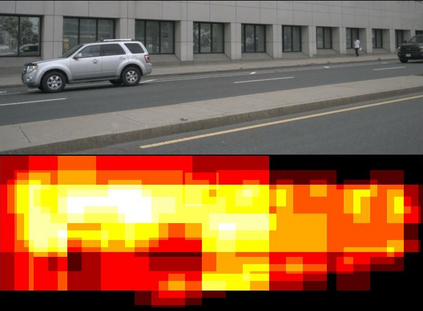
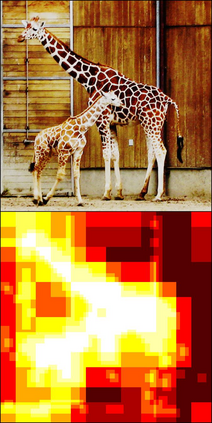
High-resolution images enable neural networks to learn richer visual representations. However, this improved performance comes at the cost of growing computational complexity, hindering their usage in latency-sensitive applications. As not all pixels are equal, skipping computations for less-important regions offers a simple and effective measure to reduce the computation. This, however, is hard to be translated into actual speedup for CNNs since it breaks the regularity of the dense convolution workload. In this paper, we introduce SparseViT that revisits activation sparsity for recent window-based vision transformers (ViTs). As window attentions are naturally batched over blocks, actual speedup with window activation pruning becomes possible: i.e., ~50% latency reduction with 60% sparsity. Different layers should be assigned with different pruning ratios due to their diverse sensitivities and computational costs. We introduce sparsity-aware adaptation and apply the evolutionary search to efficiently find the optimal layerwise sparsity configuration within the vast search space. SparseViT achieves speedups of 1.5x, 1.4x, and 1.3x compared to its dense counterpart in monocular 3D object detection, 2D instance segmentation, and 2D semantic segmentation, respectively, with negligible to no loss of accuracy.
翻译:高分辨率图像可以使神经网络学习到更丰富的视觉表示。然而,这种改进的性能是以不断增长的计算复杂度为代价的,限制了它们在延迟敏感型应用中的使用。由于并非所有像素都是相等的,因此跳过对不重要区域的计算可以提供一种简单有效的措施来减少计算。然而,由于这破坏了密集卷积负载的规律性,因此很难将其转化为CNN的实际加速。在本文中,我们引入了SparseViT,该算法重访了最近的基于窗口的Vision Transformer(ViTs)中的激活稀疏性。由于窗口注意力自然地被批处理为块,因此使用窗口激活剪枝可以实现实际的加速:即通过不到60%的稀疏性实现约50%的延迟降低。由于各层的敏感度和计算成本不同,因此应为不同的层分配不同的修剪比例。我们引入了稀疏感知适应和应用进化搜索,在广阔的搜索空间中有效地找到了最佳的层稀疏配置。SparseViT在单目三维物体检测,二维实例分割和二维语义分割中与其密集对应方法相比实现了1.5x,1.4x和1.3x的加速,几乎没有损失精度。