【论文推荐】最新六篇主题模型相关论文—动态主题模型、主题趋势、大规模并行采样、随机采样、非参主题建模
【导读】专知内容组今天推出最新六篇主题模型(Topic Model)相关论文,欢迎查看!
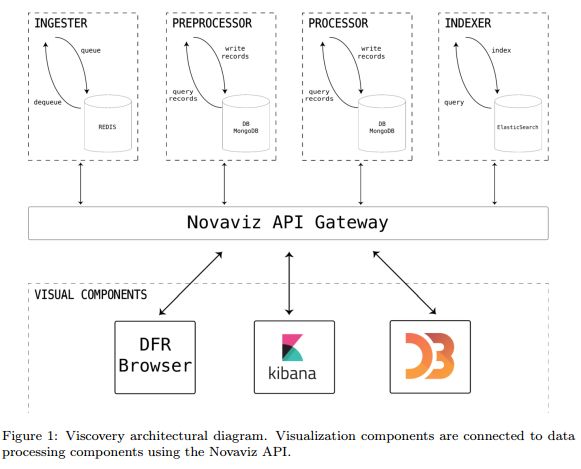
1.Viscovery: Trend Tracking in Opinion Forums based on Dynamic Topic Models(Viscovery:基于动态主题模型观点论坛的趋势跟踪)
作者:Ignacio Espinoza,Marcelo Mendoza,Pablo Ortega,Daniel Rivera,Fernanda Weiss
机构:Universidad T´ecnica Federico Santa Mar´ıa
摘要:Opinions in forums and social networks are released by millions of people due to the increasing number of users that use Web 2.0 platforms to opine about brands and organizations. For enterprises or government agencies it is almost impossible to track what people say producing a gap between user needs/expectations and organizations actions. To bridge this gap we create Viscovery, a platform for opinion summarization and trend tracking that is able to analyze a stream of opinions recovered from forums. To do this we use dynamic topic models, allowing to uncover the hidden structure of topics behind opinions, characterizing vocabulary dynamics. We extend dynamic topic models for incremental learning, a key aspect needed in Viscovery for model updating in near-real time. In addition, we include in Viscovery sentiment analysis, allowing to separate positive/negative words for a specific topic at different levels of granularity. Viscovery allows to visualize representative opinions and terms in each topic. At a coarse level of granularity, the dynamic of the topics can be analyzed using a 2D topic embedding, suggesting longitudinal topic merging or segmentation. In this paper we report our experience developing this platform, sharing lessons learned and opportunities that arise from the use of sentiment analysis and topic modeling in real world applications.
期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/f6dc886b856bc775633d21f0c43be443
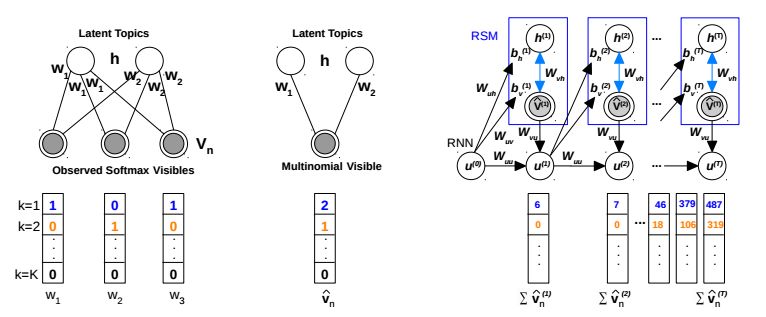
2.Deep Temporal-Recurrent-Replicated-Softmax for Topical Trends over Time(随时间演变的基于深度Temporal-Recurrent-Replicated-Softmax的主题趋势)
作者:Pankaj Gupta,Subburam Rajaram,Hinrich Schütze,Bernt Andrassy
NAACL-HLT 2018
机构:University of Munich
摘要:Dynamic topic modeling facilitates the identification of topical trends over time in temporal collections of unstructured documents. We introduce a novel unsupervised neural dynamic topic model named as Recurrent Neural Network-Replicated Softmax Model (RNNRSM), where the discovered topics at each time influence the topic discovery in the subsequent time steps. We account for the temporal ordering of documents by explicitly modeling a joint distribution of latent topical dependencies over time, using distributional estimators with temporal recurrent connections. Applying RNN-RSM to 19 years of articles on NLP research, we demonstrate that compared to state-of-the art topic models, RNNRSM shows better generalization, topic interpretation, evolution and trends. We also introduce a metric (named as SPAN) to quantify the capability of dynamic topic model to capture word evolution in topics over time.
期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/4a4d7b3da005c3d84950f36928b9d1eb
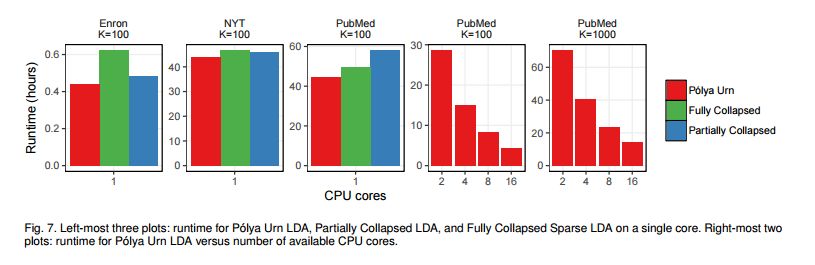
3.Polya Urn Latent Dirichlet Allocation: a doubly sparse massively parallel sampler(Polya Urn Latent Dirichlet Allocation:一个双稀疏的大规模并行采样方法)
作者:Alexander Terenin,Måns Magnusson,Leif Jonsson,David Draper
摘要:Latent Dirichlet Allocation (LDA) is a topic model widely used in natural language processing and machine learning. Most approaches to training the model rely on iterative algorithms, which makes it difficult to run LDA on big corpora that are best analyzed in parallel and distributed computational environments. Indeed, current approaches to parallel inference either don't converge to the correct posterior or require storage of large dense matrices in memory. We present a novel sampler that overcomes both problems, and we show that this sampler is faster, both empirically and theoretically, than previous Gibbs samplers for LDA. We do so by employing a novel P\'olya-urn-based approximation in the sparse partially collapsed sampler for LDA. We prove that the approximation error vanishes with data size, making our algorithm asymptotically exact, a property of importance for large-scale topic models. In addition, we show, via an explicit example, that -- contrary to popular belief in the topic modeling literature -- partially collapsed samplers can be more efficient than fully collapsed samplers. We conclude by comparing the performance of our algorithm with that of other approaches on well-known corpora.
期刊:arXiv, 2018年4月23日
网址:
http://www.zhuanzhi.ai/document/5597b716e095f10e3fe9d8c3011be251
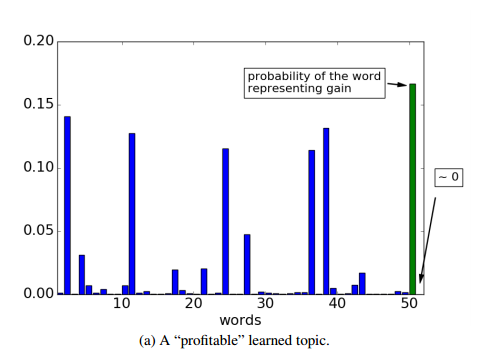
4.Overlapping Coalition Formation via Probabilistic Topic Modeling(基于概率主题模型的重叠联盟形成)
作者:Michalis Mamakos,Georgios Chalkiadakis
To appear in AAMAS'18
机构:Northwestern University,Technical University of Crete
摘要:Research in cooperative games often assumes that agents know the coalitional values with certainty, and that they can belong to one coalition only. By contrast, this work assumes that the value of a coalition is based on an underlying collaboration structure emerging due to existing but unknown relations among the agents; and that agents can form overlapping coalitions. Specifically, we first propose Relational Rules, a novel representation scheme for cooperative games with overlapping coalitions, which encodes the aforementioned relations, and which extends the well-known MC-nets representation to this setting. We then present a novel decision-making method for decentralized overlapping coalition formation, which exploits probabilistic topic modeling, and in particular, online Latent Dirichlet Allocation. By interpreting formed coalitions as documents, agents can effectively learn topics that correspond to profitable collaboration structures.
期刊:arXiv, 2018年4月14日
网址:
http://www.zhuanzhi.ai/document/817e358c94ffb0b4967c34fb1f98987c
5.Large-Scale Stochastic Sampling from the Probability Simplex(概率单纯形的大规模随机采样)
作者:Jack Baker,Paul Fearnhead,Emily B Fox,Christopher Nemeth
机构:University of Washington,Lancaster University
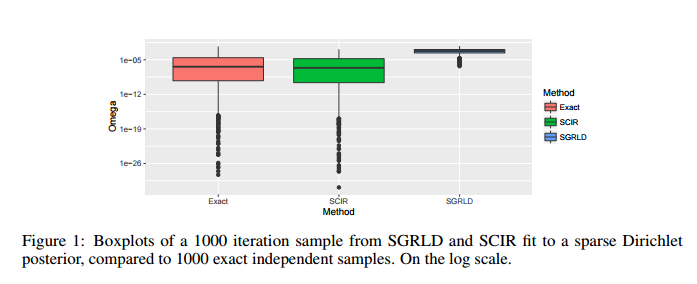
摘要:Stochastic gradient Markov chain Monte Carlo (SGMCMC) has become a popular method for scalable Bayesian inference. These methods are based on sampling a discrete-time approximation to a continuous time process, such as the Langevin diffusion. When applied to distributions defined on a constrained space, such as the simplex, the time-discretisation error can dominate when we are near the boundary of the space. We demonstrate that while current SGMCMC methods for the simplex perform well in certain cases, they struggle with sparse simplex spaces; when many of the components are close to zero. However, most popular large-scale applications of Bayesian inference on simplex spaces, such as network or topic models, are sparse. We argue that this poor performance is due to the biases of SGMCMC caused by the discretization error. To get around this, we propose the stochastic CIR process, which removes all discretization error and we prove that samples from the stochastic CIR process are asymptotically unbiased. Use of the stochastic CIR process within a SGMCMC algorithm is shown to give substantially better performance for a topic model and a Dirichlet process mixture model than existing SGMCMC approaches.
期刊:arXiv, 2018年6月19日
网址:
http://www.zhuanzhi.ai/document/a7256ae91be0736bd81473b0d133c6fc
6.Nonparametric Topic Modeling with Neural Inference(非参主题建模与神经推理)
作者:Xuefei Ning,Yin Zheng,Zhuxi Jiang,Yu Wang,Huazhong Yang,Junzhou Huang
机构:Tsinghua University
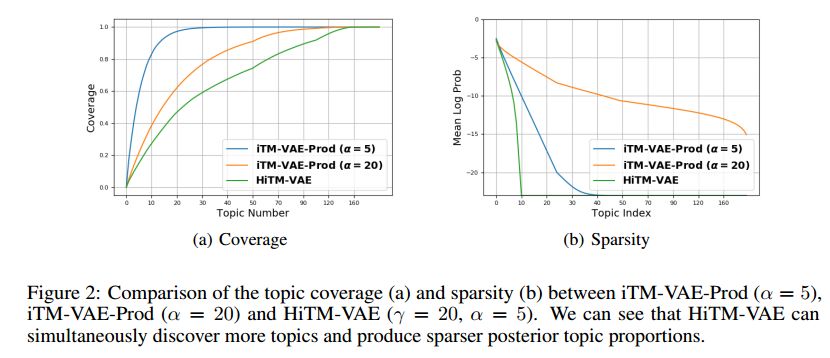
摘要:This work focuses on combining nonparametric topic models with Auto-Encoding Variational Bayes (AEVB). Specifically, we first propose iTM-VAE, where the topics are treated as trainable parameters and the document-specific topic proportions are obtained by a stick-breaking construction. The inference of iTM-VAE is modeled by neural networks such that it can be computed in a simple feed-forward manner. We also describe how to introduce a hyper-prior into iTM-VAE so as to model the uncertainty of the prior parameter. Actually, the hyper-prior technique is quite general and we show that it can be applied to other AEVB based models to alleviate the {\it collapse-to-prior} problem elegantly. Moreover, we also propose HiTM-VAE, where the document-specific topic distributions are generated in a hierarchical manner. HiTM-VAE is even more flexible and can generate topic distributions with better variability. Experimental results on 20News and Reuters RCV1-V2 datasets show that the proposed models outperform the state-of-the-art baselines significantly. The advantages of the hyper-prior technique and the hierarchical model construction are also confirmed by experiments.
期刊:arXiv, 2018年6月18日
网址:
http://www.zhuanzhi.ai/document/6cff57dd7505ae7ddbae6925cb8fd1cf
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知



