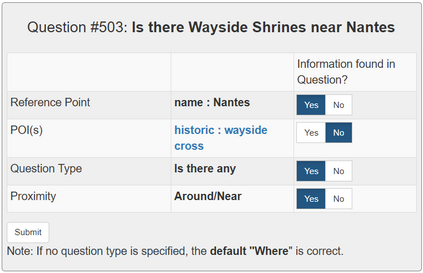
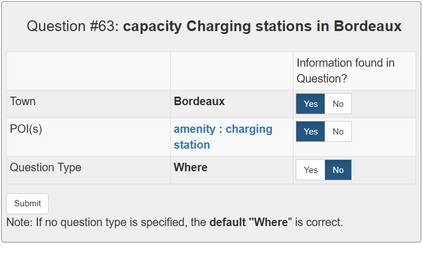
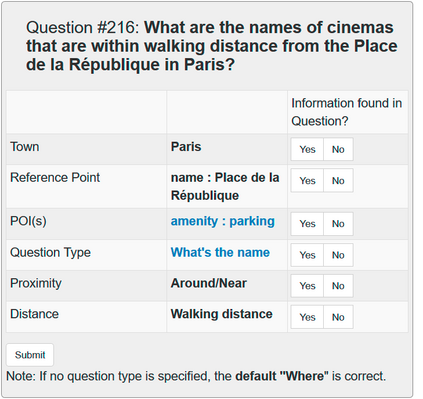
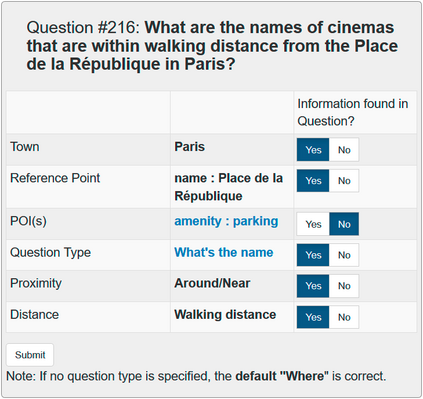
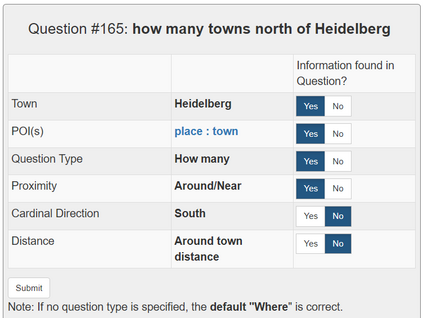
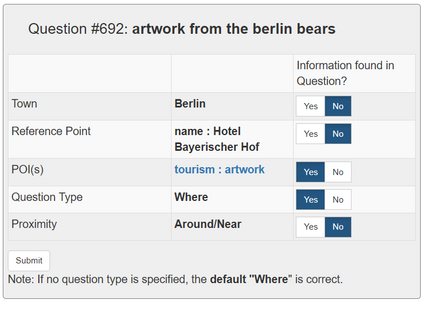
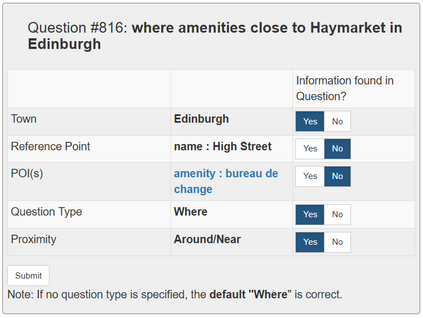
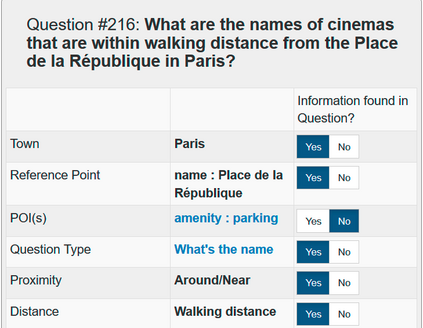
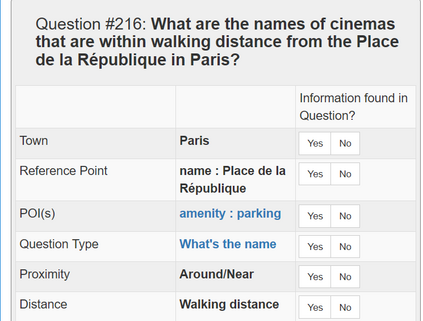
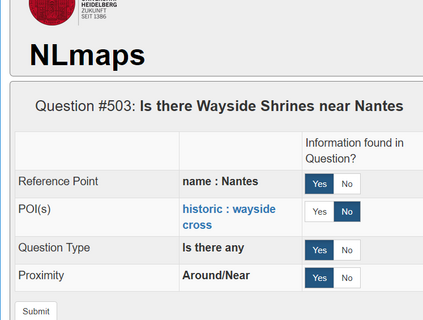
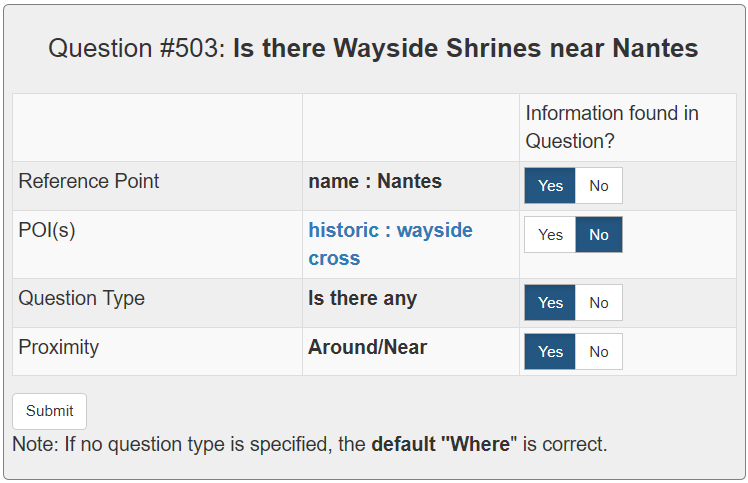
In semantic parsing for question-answering, it is often too expensive to collect gold parses or even gold answers as supervision signals. We propose to convert model outputs into a set of human-understandable statements which allow non-expert users to act as proofreaders, providing error markings as learning signals to the parser. Because model outputs were suggested by a historic system, we operate in a counterfactual, or off-policy, learning setup. We introduce new estimators which can effectively leverage the given feedback and which avoid known degeneracies in counterfactual learning, while still being applicable to stochastic gradient optimization for neural semantic parsing. Furthermore, we discuss how our feedback collection method can be seamlessly integrated into deployed virtual personal assistants that embed a semantic parser. Our work is the first to show that semantic parsers can be improved significantly by counterfactual learning from logged human feedback data.
翻译:在用于解答问题的语义解析中,收集金粒或甚至金质解答作为监督信号往往太昂贵。 我们提议将模型输出转换成一套人类无法理解的语句,让非专家用户能够充当校对员,提供错误标记作为给分析员的学习信号。 由于模型输出是由历史系统建议的,我们是在反事实或非政策、学习设置中运作的。 我们引入了新的估算器,可以有效地利用给定反馈,避免反事实学习中已知的畸形,同时仍然适用于神经语义解析的随机梯度梯度优化。 此外,我们讨论了我们的反馈收集方法如何被无缝地整合到部署的虚拟个人助手中,以嵌入语义解析器。我们的工作首先表明,从登录的人类反馈数据中进行反事实学习,可以大大改进语义解剖析器。