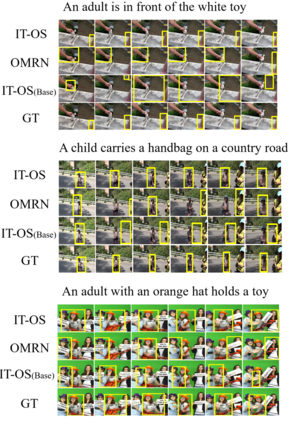
Natural language spatial video grounding aims to detect the relevant objects in video frames with descriptive sentences as the query. In spite of the great advances, most existing methods rely on dense video frame annotations, which require a tremendous amount of human effort. To achieve effective grounding under a limited annotation budget, we investigate one-shot video grounding, and learn to ground natural language in all video frames with solely one frame labeled, in an end-to-end manner. One major challenge of end-to-end one-shot video grounding is the existence of videos frames that are either irrelevant to the language query or the labeled frames. Another challenge relates to the limited supervision, which might result in ineffective representation learning. To address these challenges, we designed an end-to-end model via Information Tree for One-Shot video grounding (IT-OS). Its key module, the information tree, can eliminate the interference of irrelevant frames based on branch search and branch cropping techniques. In addition, several self-supervised tasks are proposed based on the information tree to improve the representation learning under insufficient labeling. Experiments on the benchmark dataset demonstrate the effectiveness of our model.
翻译:尽管取得了巨大进展,但大多数现有方法都依赖于密集的视频框架说明,这需要大量人力投入。为了在有限的批注预算下实现有效的地面定位,我们调查了一次性的视频地面定位,并学习在所有视频框架中以一个标有端对端标签的框架来定位自然语言。端到端一发视频地面定位的一个重大挑战是存在与语言查询或标签框无关的视频框架。另一个挑战涉及监督有限,这可能导致无法有效地进行代表性学习。为了应对这些挑战,我们设计了一个通过信息树为一流视频地面定位设计的终端到终端模型(IT-OS)。它的关键模块,即信息树,可以消除基于分支搜索和分支裁剪技术的不相关框架的干扰。此外,根据信息树提出了几项自封任务,以改进在标签不足下的代表学习。基准数据模型实验显示了我们模型的有效性。