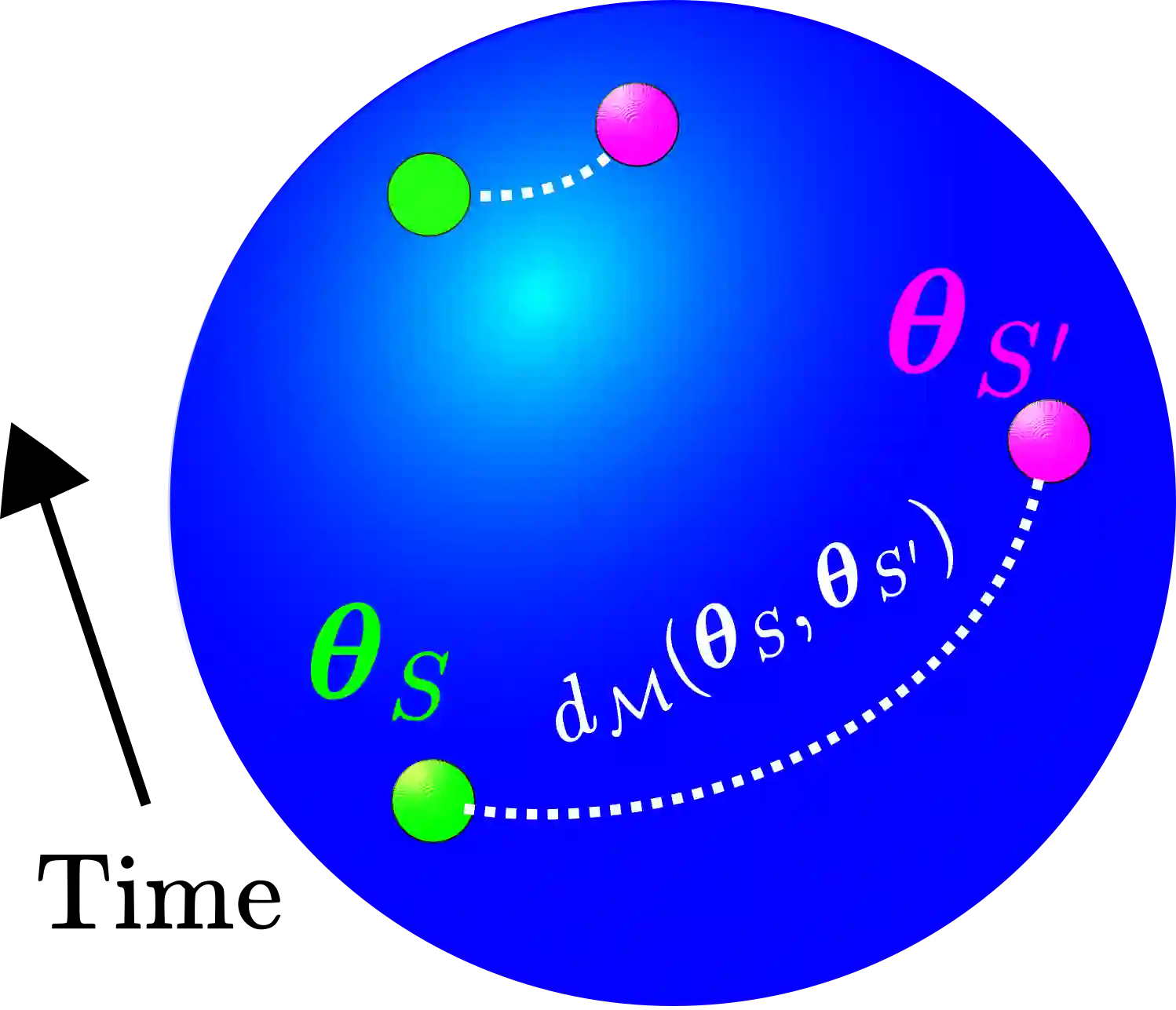
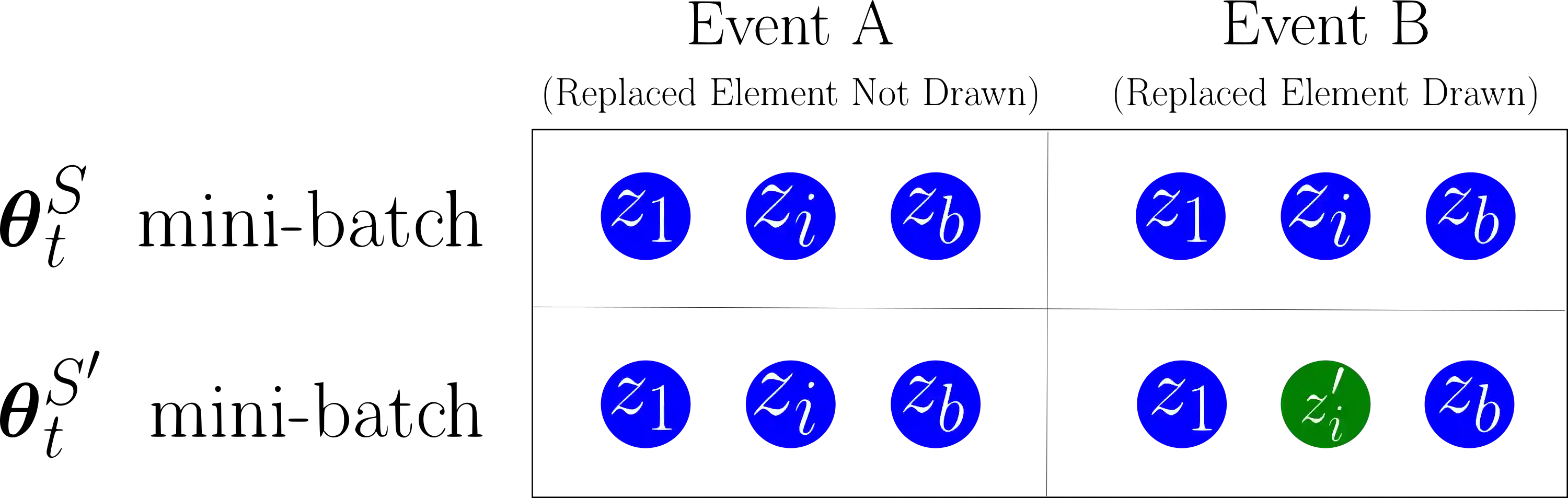
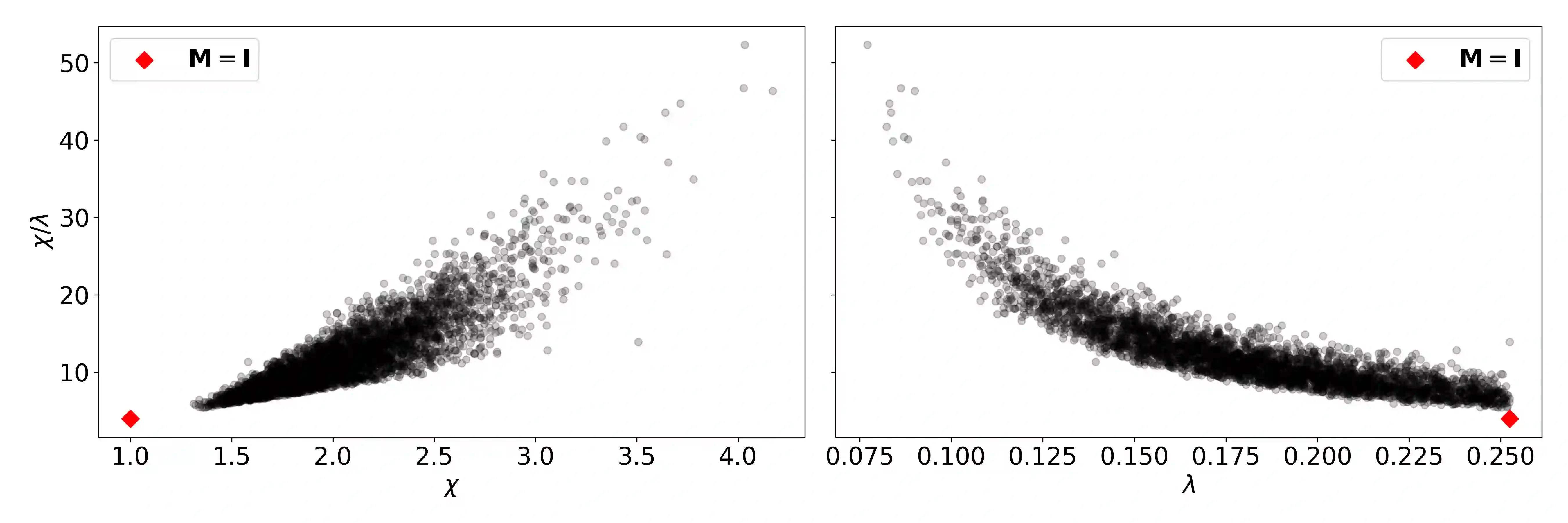
We prove that Riemannian contraction in a supervised learning setting implies generalization. Specifically, we show that if an optimizer is contracting in some Riemannian metric with rate $\lambda > 0$, it is uniformly algorithmically stable with rate $\mathcal{O}(1/\lambda n)$, where $n$ is the number of labelled examples in the training set. The results hold for stochastic and deterministic optimization, in both continuous and discrete-time, for convex and non-convex loss surfaces. The associated generalization bounds reduce to well-known results in the particular case of gradient descent over convex or strongly convex loss surfaces. They can be shown to be optimal in certain linear settings, such as kernel ridge regression under gradient flow.
翻译:我们证明,在受监督的学习环境中,里曼尼人的收缩意味着概括化。具体地说,我们证明,如果一个优化者在某种里曼度标准中以$/lambda > 0美元收缩,那么它就具有统一的逻辑稳定性,以$\mathcal{O}(1/\lambda n)美元收缩,而美元是培训中贴有标签的例子的数量。结果显示,在连续和离散的时间里,对二次曲线和非二次曲线损失表面进行随机和确定性优化。相关的一般化结合在峰值或强二次曲线损失表面的梯度下降的特定情况下,会降低到众所周知的结果。在某些线性环境,例如梯度流下的内核脊回归,这些结果可以证明是最佳的。