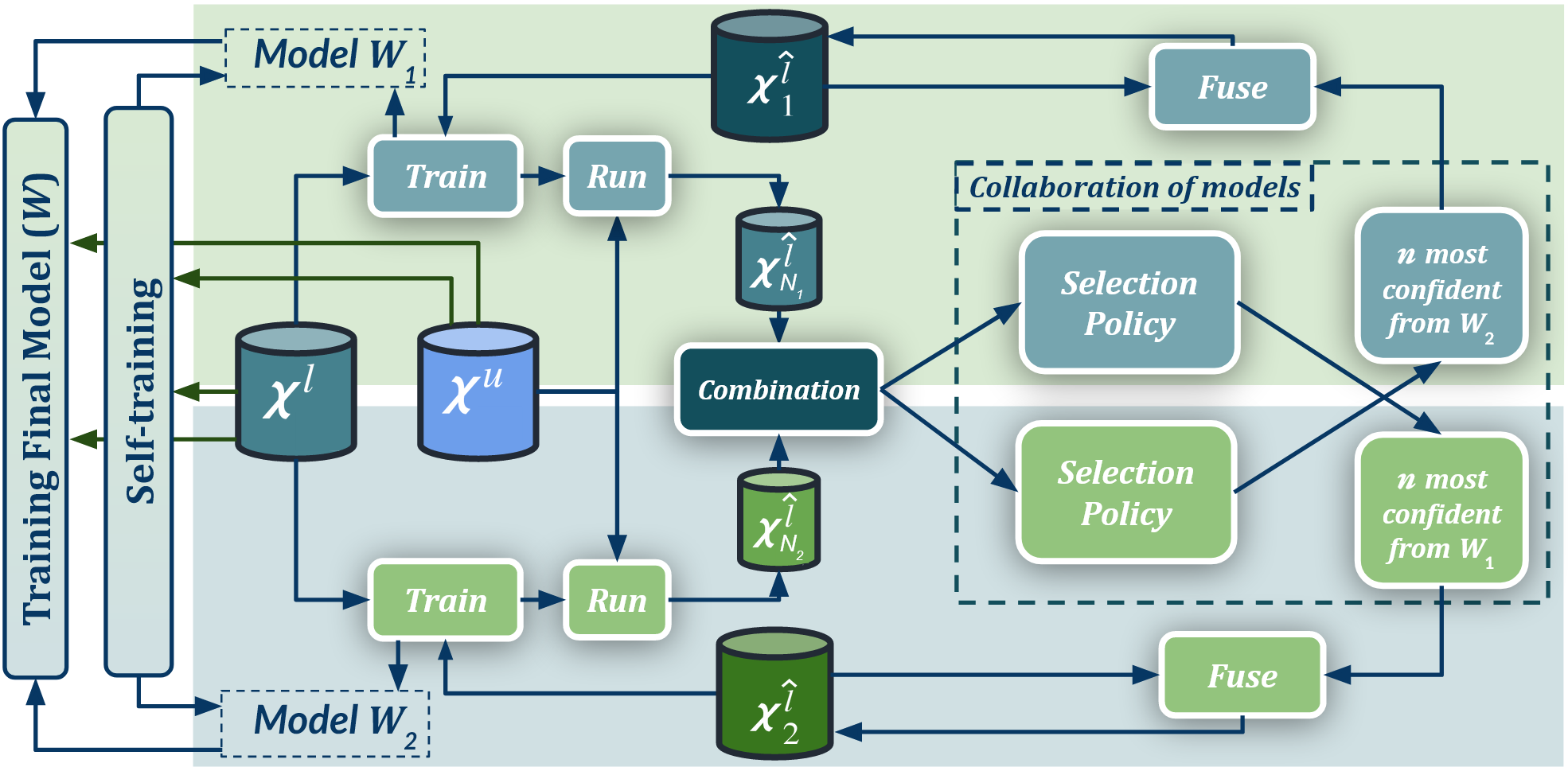
Semantic image segmentation is addressed by training deep models. Since supervised training draws to a curse of human-based image labeling, using synthetic images with automatically generated ground truth together with unlabeled real-world images is a promising alternative. This implies to address an unsupervised domain adaptation (UDA) problem. In this paper, we proposed a new co-training process for synth-to-real UDA of semantic segmentation models. First, we design a self-training procedure which provides two initial models. Then, we keep training these models in a collaborative manner for obtaining the final model. The overall process treats the deep models as black boxes and drives their collaboration at the level of pseudo-labeled target images, i.e., neither modifying loss functions is required, nor explicit feature alignment. We test our proposal on standard synthetic and real-world datasets. Our co-training shows improvements of 15-20 percentage points of mIoU over baselines, so establishing new state-of-the-art results.
翻译:语义图像分解由培养深层模型处理。 由于受监督的培训将人类图像标签的诅咒引向人类图像标签的诅咒, 使用自动生成地面真象的合成图像和未贴标签的现实世界图像是一个很有希望的替代办法。 这意味着要解决一个不受监督的域适应问题。 在本文中, 我们提出了一个新的语义分解模型合成和真实 UDA 联合培训程序。 首先, 我们设计了一个自我培训程序, 提供两个初始模型。 然后, 我们继续以协作的方式培训这些模型, 以获得最终模型。 总体过程将深层模型作为黑盒, 并将它们的合作推进到假标签目标图像的水平上, 也就是说, 不需要修改损失函数, 也不需要明确的特性校准。 我们测试我们关于标准合成和真实世界数据集的建议。 我们的共同培训显示比基线改进了 mIoU 15-20 个百分点的 mIoU, 从而建立新的状态结果 。