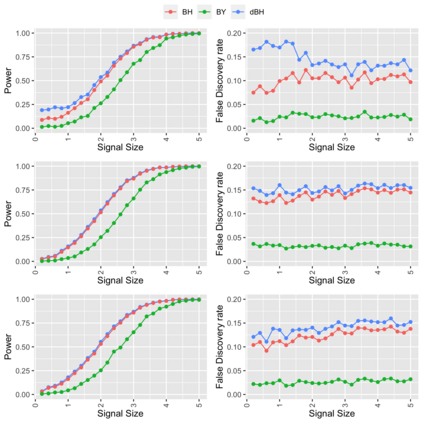
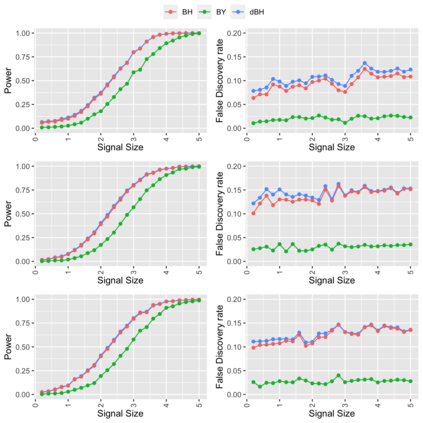
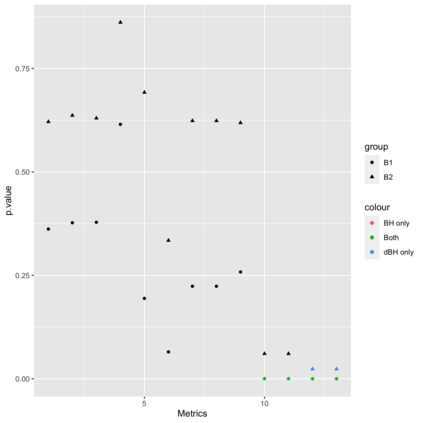
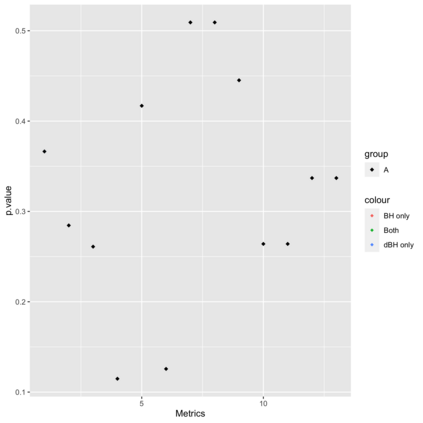
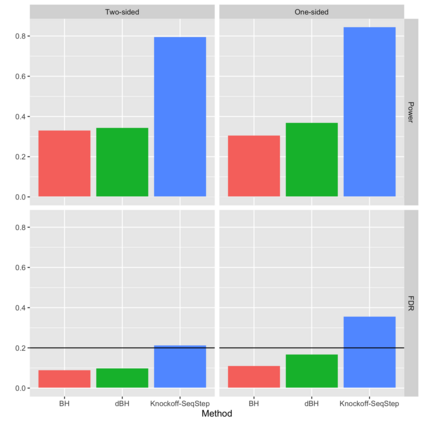
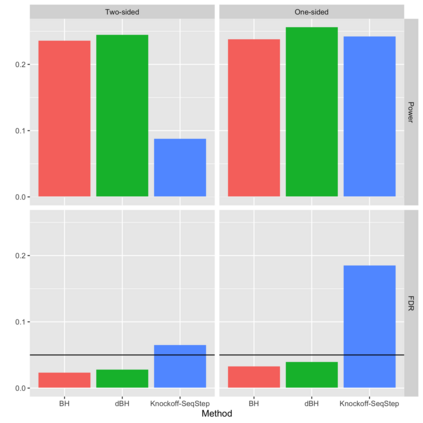
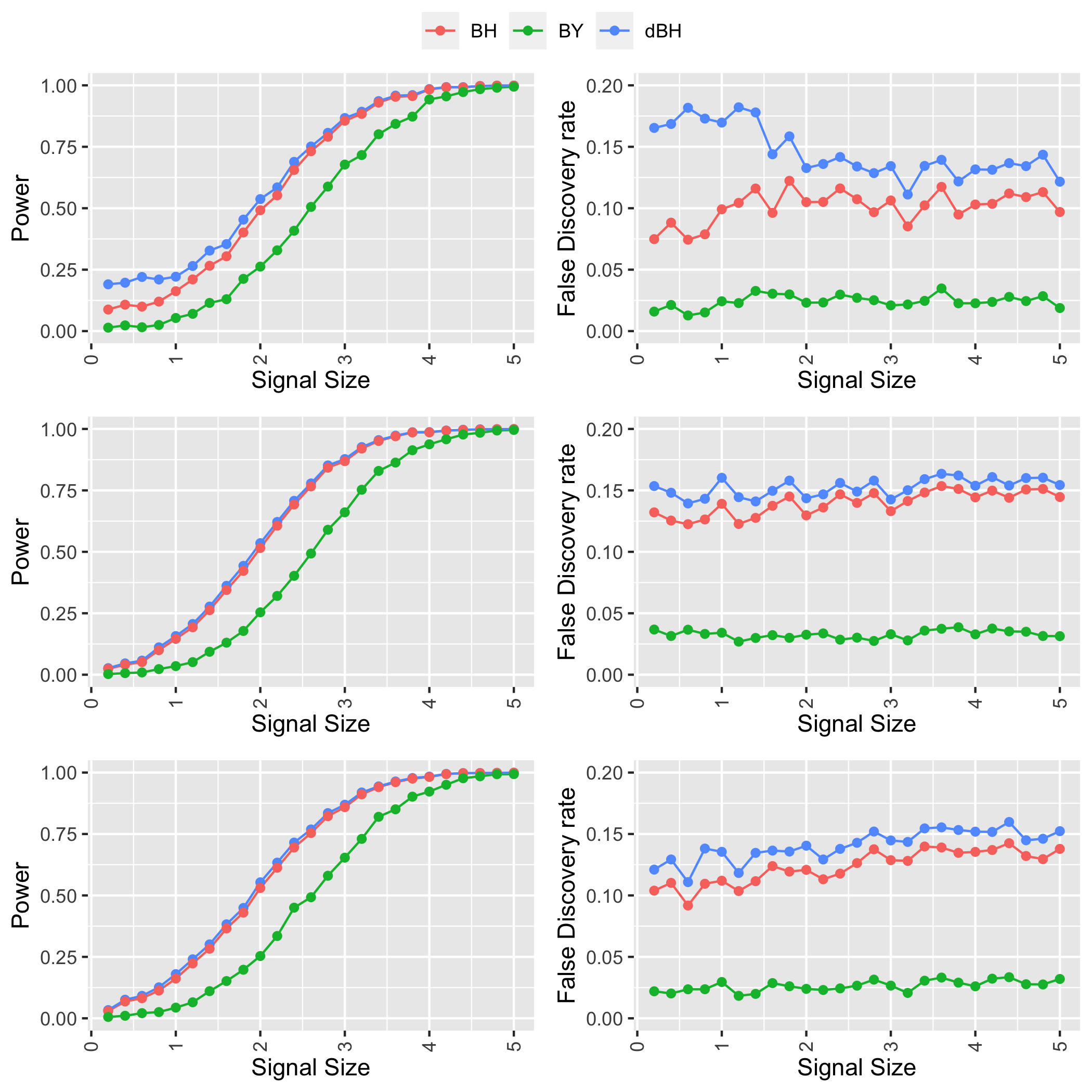
Online controlled experiments (also known as A/B Testing) have been viewed as a golden standard for large data-driven companies since the last few decades. The most common A/B testing framework adopted by many companies use "average treatment effect" (ATE) as statistics. However, it remains a difficult problem for companies to improve the power of detecting ATE while controlling "false discovery rate" (FDR) at a predetermined level. One of the most popular FDR-control algorithms is BH method, but BH method is only known to control FDR under restrictive positive dependence assumptions with a conservative bound. In this paper, we propose statistical methods that can systematically and accurately identify ATE, and demonstrate how they can work robustly with controlled low FDR but a higher power using both simulation and real-world experimentation data. Moreover, we discuss the scalability problem in detail and offer comparison of our paradigm to other more recent FDR control methods, e.g., knockoff, AdaPT procedure, etc.
翻译:自过去几十年以来,对大型数据驱动公司来说,在线控制实验(又称A/B测试)一直被视为一个黄金标准。许多公司采用的最常见A/B测试框架使用“平均处理效果”作为统计数据。然而,对于公司来说,在预先控制“假发现率”的同时,提高检测ATE的能力仍然是一个困难的问题。最受欢迎的FDR控制算法之一是BH方法,但BH方法只知道在限制性的正面依赖假设下,以保守约束控制FDR。在本文件中,我们提出了能够系统和准确地识别ATE的统计方法,并表明它们如何用模拟和现实实验数据与受控的低FDR(平均处理效果)进行强有力的工作,但能以更高的功率进行模拟和现实实验数据。此外,我们详细讨论了可扩缩性问题,并将我们的范式与其他最新的FDR控制方法(如敲门、ADPT程序等)进行比较。