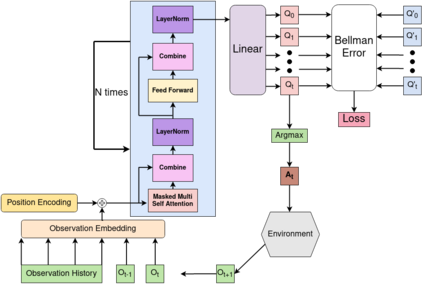
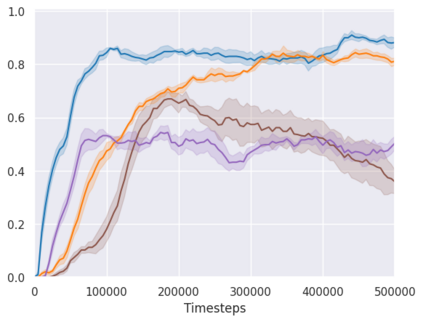
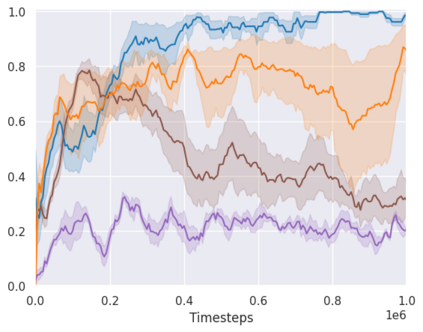
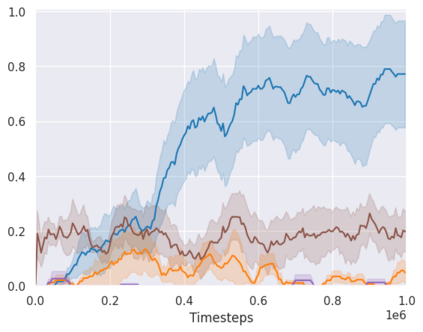
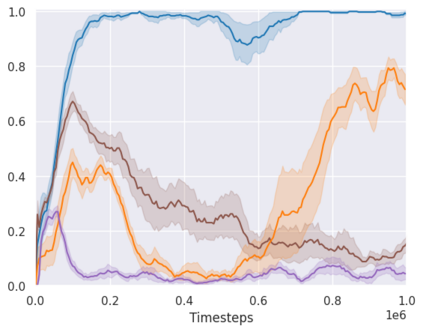
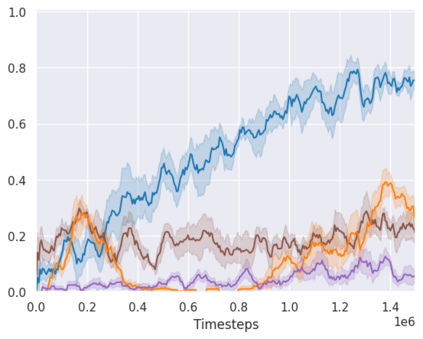
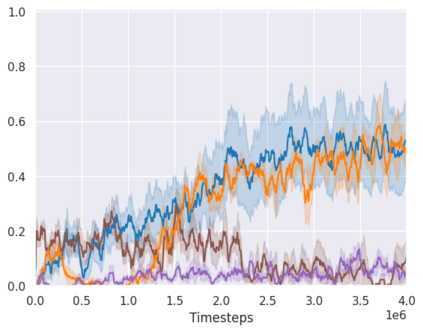
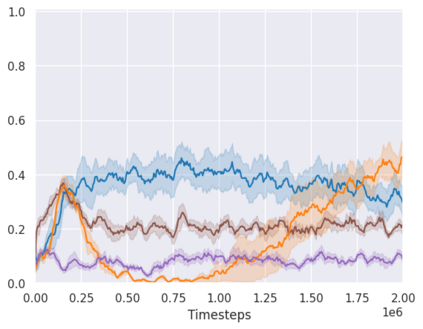
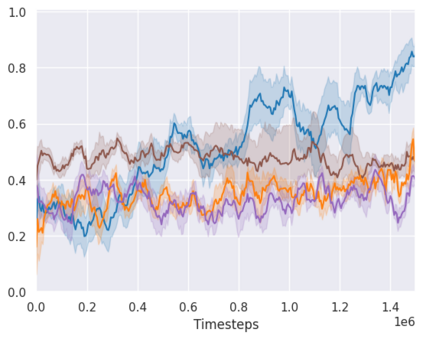
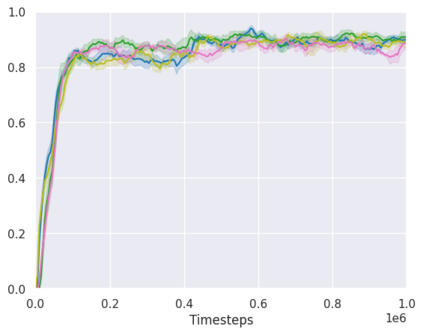
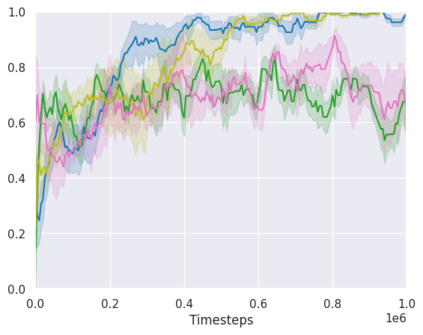
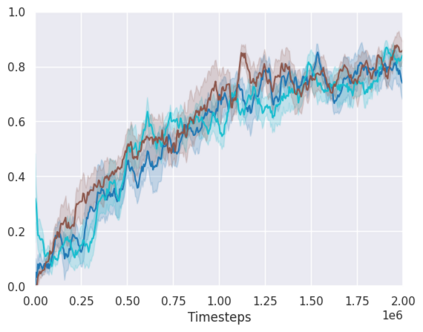
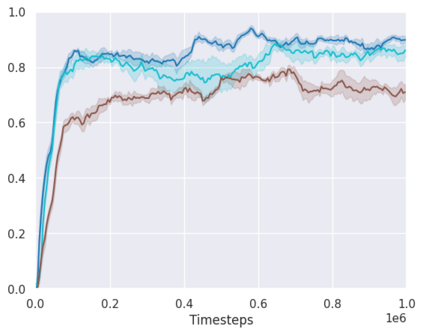
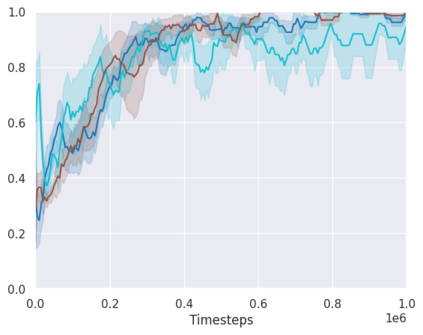
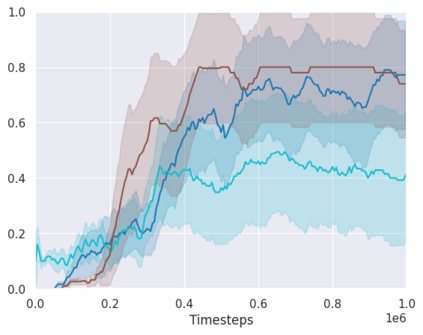
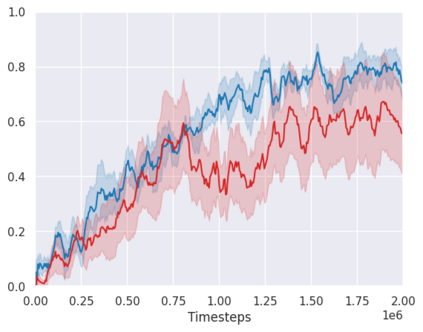
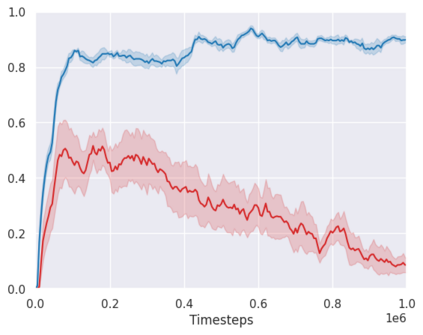
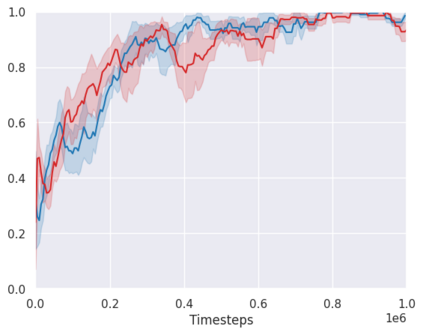
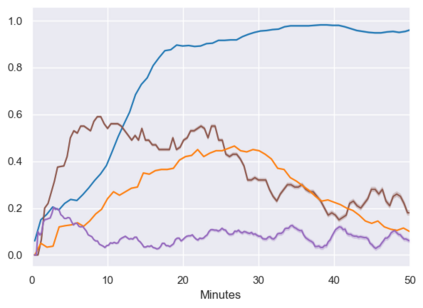
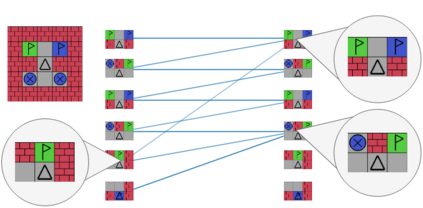
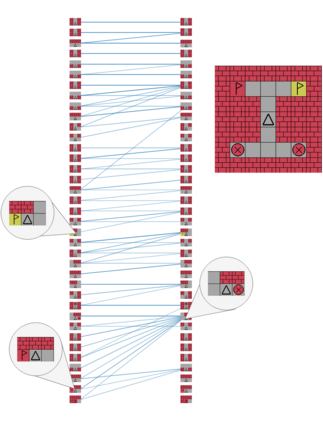
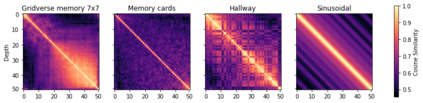
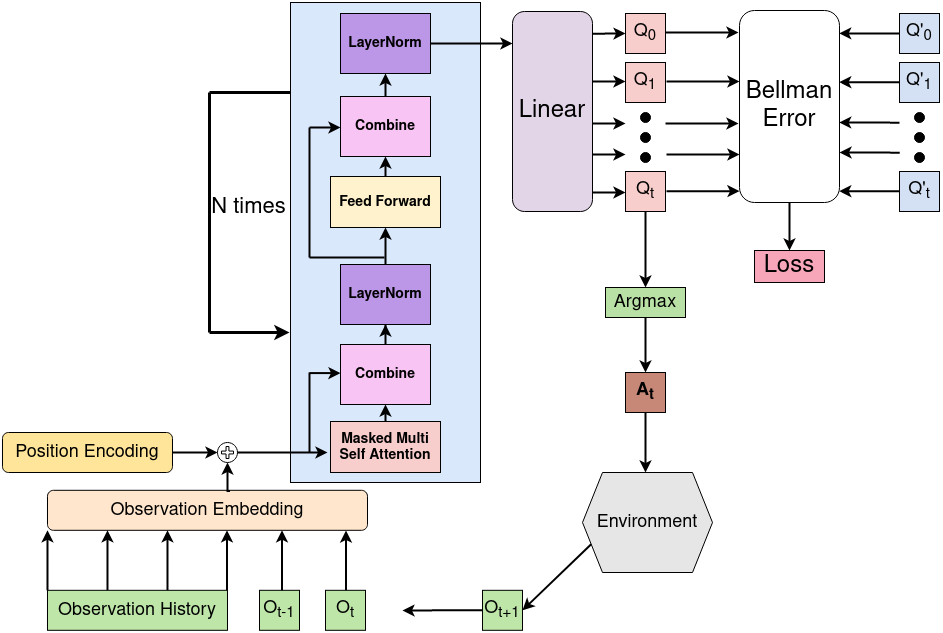
Real-world reinforcement learning tasks often involve some form of partial observability where the observations only give a partial or noisy view of the true state of the world. Such tasks typically require some form of memory, where the agent has access to multiple past observations, in order to perform well. One popular way to incorporate memory is by using a recurrent neural network to access the agent's history. However, recurrent neural networks in reinforcement learning are often fragile and difficult to train, susceptible to catastrophic forgetting and sometimes fail completely as a result. In this work, we propose Deep Transformer Q-Networks (DTQN), a novel architecture utilizing transformers and self-attention to encode an agent's history. DTQN is designed modularly, and we compare results against several modifications to our base model. Our experiments demonstrate the transformer can solve partially observable tasks faster and more stably than previous recurrent approaches.
翻译:现实世界强化学习任务往往涉及某种形式的部分可观察性,因为观测只对世界的真实状况提供部分或噪音的视角。这类任务通常需要某种形式的记忆,因为代理人可以接触过去多次的观察,以便很好地发挥作用。融合记忆的一种流行方式是利用一个经常性神经网络访问代理人的历史。然而,经常性的强化学习神经网络往往很脆弱,难以培训,容易发生灾难性的遗忘,有时甚至完全失败。在这项工作中,我们提议采用深变异器和自我注意来编码代理人历史的新结构。DTQN是模块设计的,我们对照对基本模型的一些修改来比较结果。我们的实验表明变异器能够比以往的重复方法更快、更精确地解决部分可观察的任务。